






八爪鱼采集数字进行翻页
在进行网页数据采集时,翻页操作是一个常见的需求,尤其是在那些需要逐页加载内容的网站。比如新闻列表、商品列表等,这些网页通常会通过点击数字页码进行翻页来加载更多的内容。八爪鱼提供了两种方式来实现这一操作:一种是使用智能识别,另一种是通过自定义配置来实现。今天,我们就来详细了解这两种方法。
八爪鱼采集器官方链接:https://affiliate.bazhuayu.com/7hypDr
一、使用智能识别实现【数字翻页】
八爪鱼的智能识别功能可以自动识别网页中的数字翻页操作。如果网页结构比较简单,并且页码是清晰可见的,八爪鱼可以通过智能识别直接识别出页码,并自动点击进行翻页。这种方式简单快捷,适用于大多数具有标准翻页结构的网页。

示例: 在八爪鱼中,你只需要选择“智能识别”功能,它会自动判断并识别网页中的页码数字。此时,八爪鱼会自动进行翻页,直到到达最后一页,完成数据采集。
二、自己配置采集流程实现【数字翻页】
如果网页结构复杂,智能识别无法准确定位翻页按钮,我们可以通过自定义配置来实现数字翻页。在这部分中,我们将介绍如何通过手动设置 XPath 来实现在八爪鱼中的循环翻页。
Step1:编写XPath定位当前页和下一页
首先,我们需要定位到当前页和下一页的按钮。以某个分页网页为例,当前页和其他页的HTML标签有所区别。我们可以利用这些区别来编写 XPath。
定位当前页
打开网页源码,找到当前页所在的元素,通常当前页的页码会有独特的标识,比如 class 属性。我们可以看到,当前页通常会用span标签标识,且其class属性为thisclass。因此,我们的 XPath 可以写成://span[@class="thisclass"]
这个 XPath 将精确定位到当前页。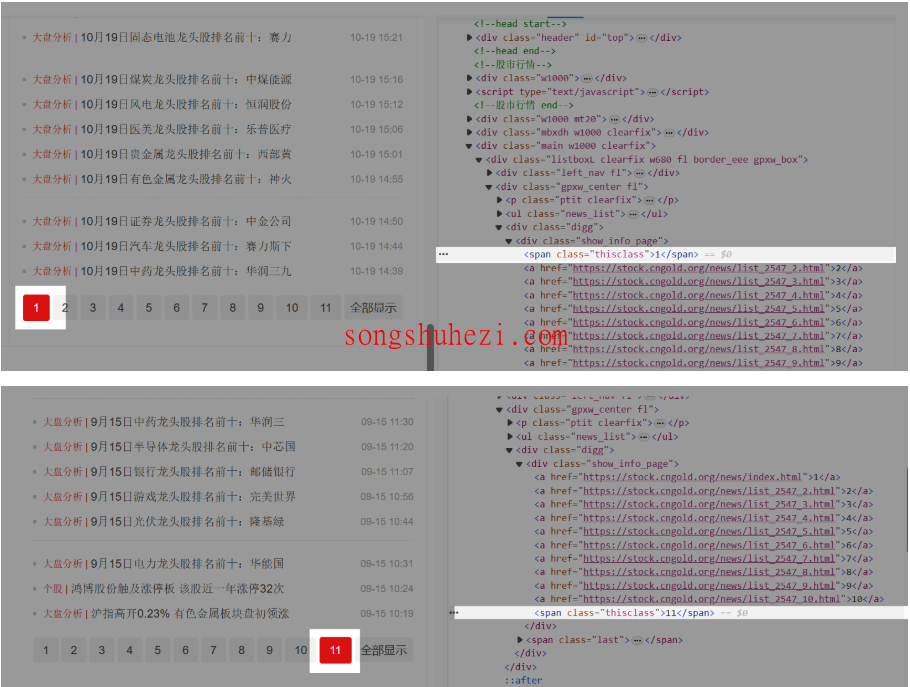
定位下一页
接下来,我们需要定位到当前页的下一页按钮。利用 XPath 的following-sibling::函数,可以定位到当前标签后面的同级标签。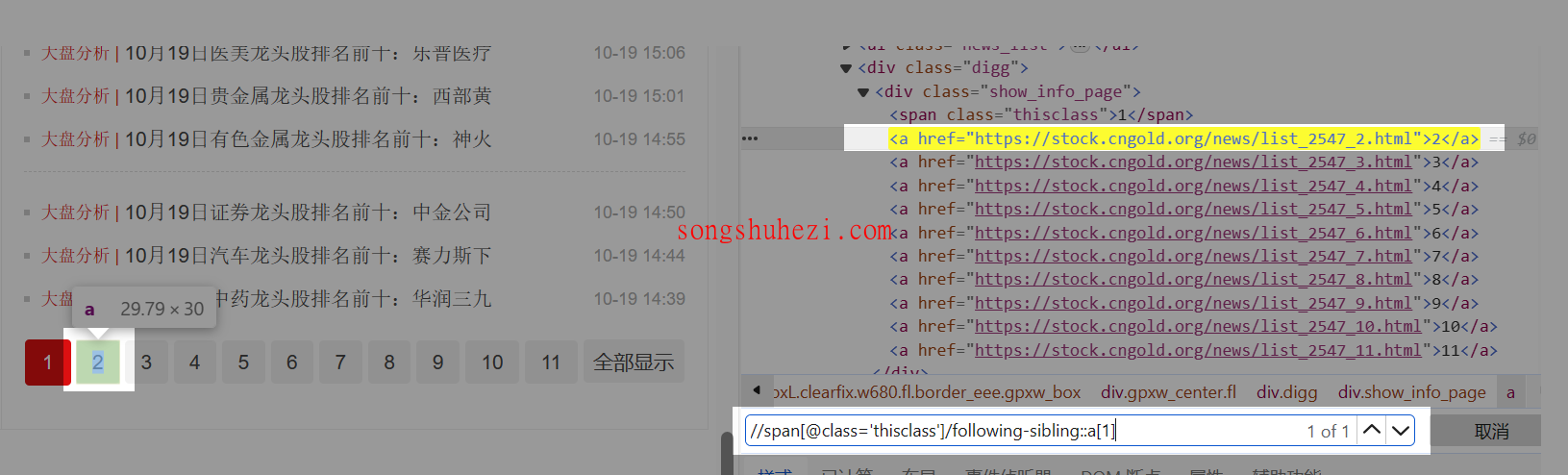
例如,
//span[@class="thisclass"]/following-sibling::a[1]就能够精确定位到当前页之后的第一个a标签,也就是下一页按钮。
Step2:在八爪鱼中创建循环翻页流程
- 创建循环步骤
进入八爪鱼客户端,打开你的采集任务,在采集流程中拖入一个“循环”步骤,选择“单个元素”循环方式。然后,将上面编写好的 XPath//span[@class="thisclass"]/following-sibling::a[1]粘贴到循环步骤中的“单个元素”文本框中,点击“确定”保存。 - 添加点击元素操作
接着,拖入一个“点击元素”步骤,设置“Ajax超时时间”为7秒(具体超时时间根据网页加载速度调整),点击“确定”保存。此时,当执行采集任务时,八爪鱼将按照设置的 XPath 自动点击翻页按钮,逐页加载并采集数据。 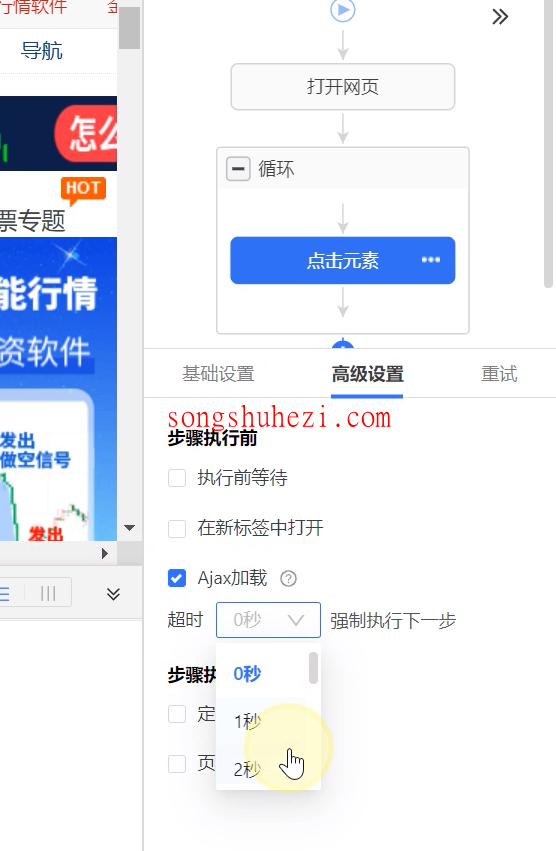
Step3:提取数据并完成任务
在完成翻页操作的配置后,我们可以按需设置数据提取规则。根据目标数据,选择合适的提取方式,例如提取新闻标题、时间、链接等。完成数据提取后,点击启动采集,八爪鱼将自动进行翻页并采集每一页的数据。
特别说明
- 多次翻页
如果你的网页有很多页,需要采集的数据又比较多,可以适当增加循环次数。八爪鱼支持设置循环次数,直到最后一页,确保所有数据都被采集。 - Ajax加载网页
有些网页使用 Ajax 技术来动态加载内容,因此翻页过程中可能会出现加载延迟。在这种情况下,设置合理的 Ajax 超时时间(例如 7秒)非常重要,以确保页面加载完成后再进行翻页。 - 注意网页结构的变化
如果网页的结构发生变化,例如页码的标识符或翻页按钮的 HTML 标签不同,记得及时调整 XPath,确保翻页操作正常进行。
总结
通过八爪鱼的智能识别功能和自定义配置功能,我们可以轻松实现数字翻页的自动化数据采集。智能识别适用于简单的翻页结构,而自定义配置则适用于复杂或特殊的翻页操作。无论是哪种方式,只要掌握了 XPath 的使用,就可以高效地采集分页网页的数据,避免手动逐页操作。希望这篇文章能帮助你更好地使用八爪鱼进行数字翻页数据采集。

反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS