






八爪鱼采集自定义定位元素
在进行数据采集时,很多时候我们会遇到字段提取不到或者字段错位的情况。其实,这主要是因为我们在定位字段时没有准确选择合适的XPath,从而导致数据提取出现问题。今天,我们来看看如何通过自定义定位元素的方式,来调整字段的定位XPath,确保数据提取的准确性。特别是对于常见的列表页和详情页数据,我们需要分别做出针对性的调整。
八爪鱼采集器官方链接:https://affiliate.bazhuayu.com/7hypDr
详情页数据的提取
假设我们需要提取一个新闻网站中的新闻详情页的数据,比如新闻的标题、是否原创、时间等字段。以今日头条为例,我们以两个新闻详情页为例,看看如何应对字段错位的情况。
Step1:采集数据
首先,我们按照需求去采集数据。比如我们要提取这两个新闻详情页中的标题、是否原创、时间等字段。采集过程中,可能会发现第二个新闻的时间字段没有提取到。这是因为第二个新闻没有“原创”字段,导致时间字段的位置发生了变化。
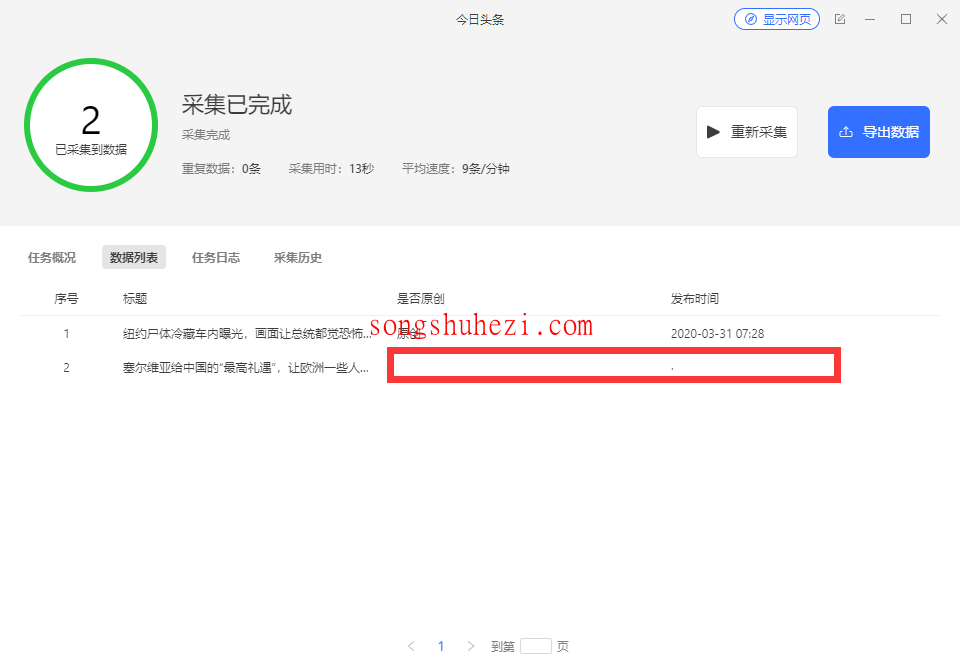
Step2:查看采集结果
在这个阶段,我们打开采集工具,观察到第二个新闻的时间字段并没有采集到。通过检查源代码发现,第二个新闻的时间字段位置有些变化,导致原本的XPath不再适用。
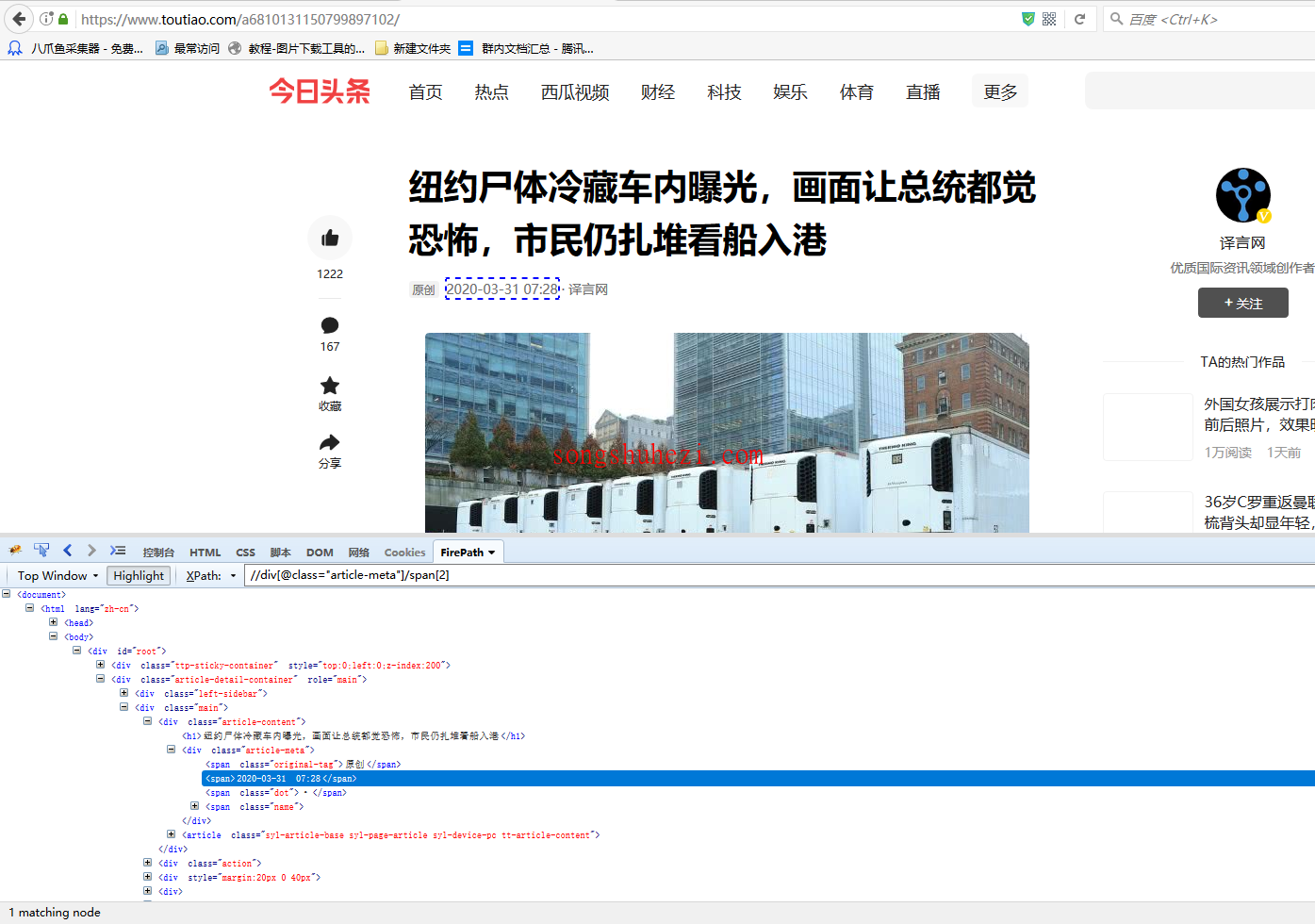
Step3:检查XPath
我们先找到时间字段的XPath,比如 //div[@class="article-meta"]/span[2]。在第一个新闻页面中,这个XPath可以准确定位到时间字段,但在第二个新闻页面中就无法定位了。
Step4:修改XPath
通过观察源码我们发现,时间字段的标签都是span,并且它位于article-meta类的元素内。由于这两个新闻页面的结构略有不同,我们可以通过修改XPath来解决这个问题。例如,我们可以使用以下XPath: //div[@class="article-meta"]//span[@class="dot"]/preceding-sibling::span[1]。这个修改后的XPath可以在两个新闻页面中都正确提取时间字段。

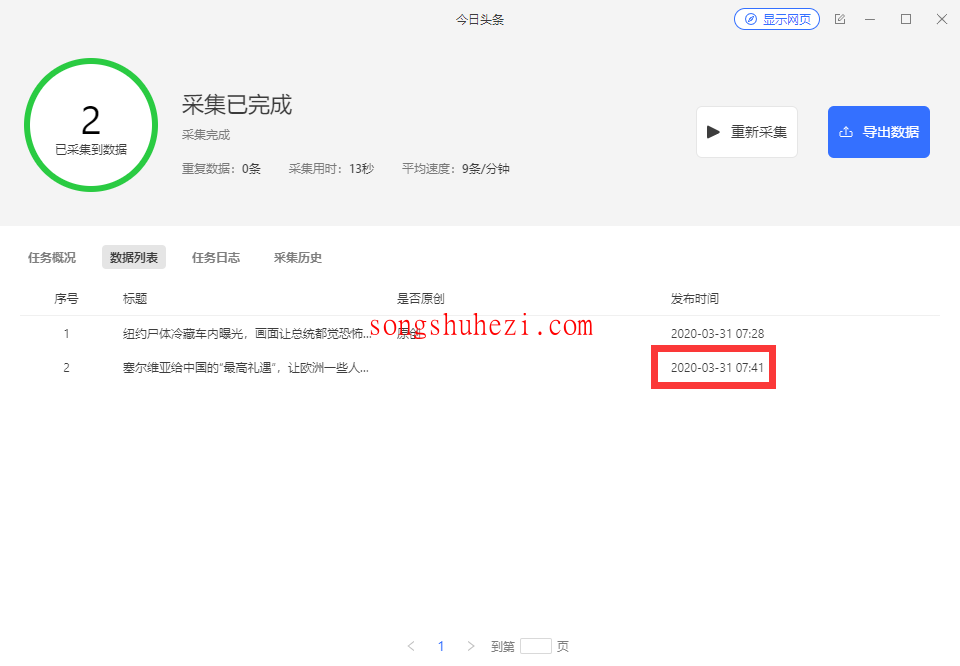
Step5:应用修改后的XPath
将修改后的XPath粘贴到采集工具中,相应的时间字段就能够正确提取出来了。
列表页数据的提取
接下来,我们来看一个列表页数据的提取问题。假设我们要采集豆瓣书籍评论页面的数据,包括评论内容、评论人、时间、地区等字段。在这个过程中,我们可能会遇到字段错位的问题。
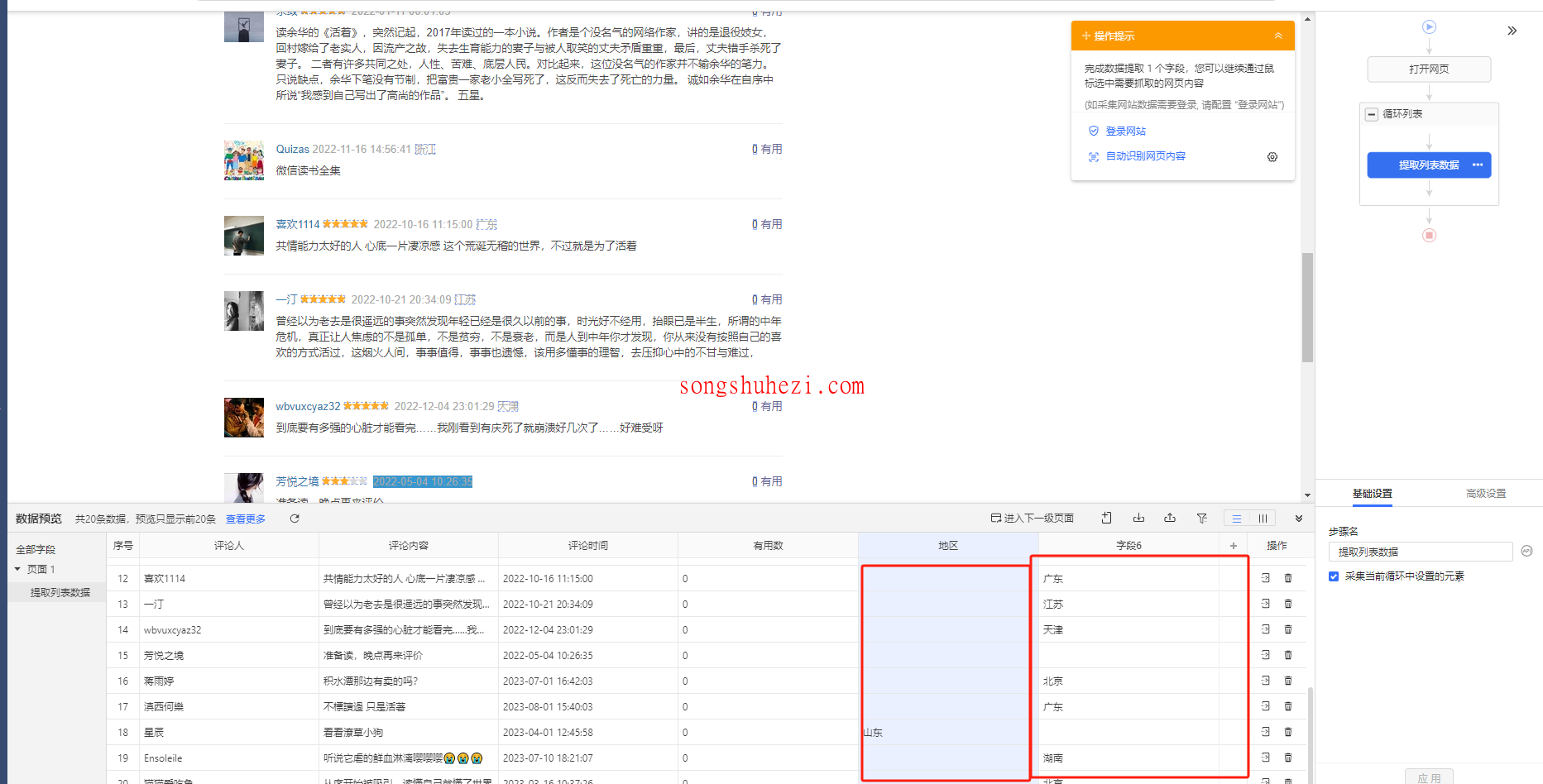
Step1:采集数据
首先,我们打开豆瓣书籍页面,按照需求提取评论、评论人、时间、地区等字段。刚开始,采集工具似乎已经正确提取了所有字段,但是我们发现“地区”字段出现了错位,数据没有完全提取出来。
Step2:排查原因
接下来,我们需要排查原因。仔细检查,发现问题出在八爪鱼自动生成的“地区”字段的XPath不够精准。具体来说,它没有涵盖所有评论项,所以出现了错位。为了解决这个问题,我们需要手动修改XPath。
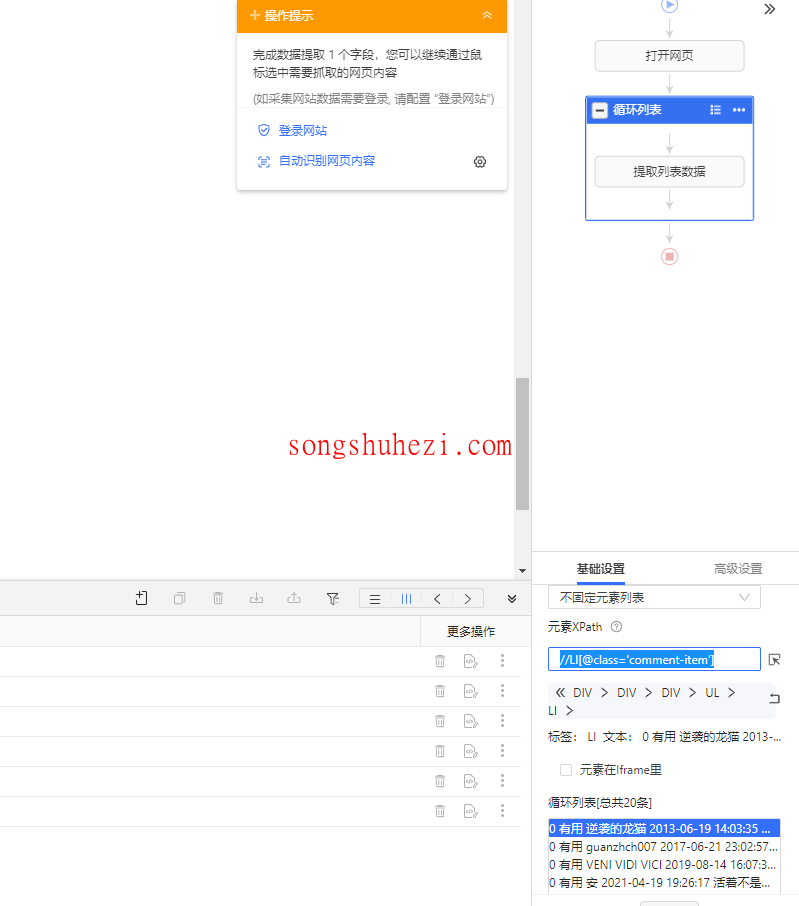
Step3:修改XPath
我们先复制当前的“地区”字段XPath,比如 /div[2]/h3[1]/span[2]/span[1],然后再复制循环框的XPath://LI[@class='comment-item']。接下来,我们将这两个XPath结合起来,得到了一个新的XPath: //LI[@class='comment-item']/div[2]/h3[1]/span[2]/span[1]。但是,检查发现并非所有“地区”字段都能被正确提取出来。
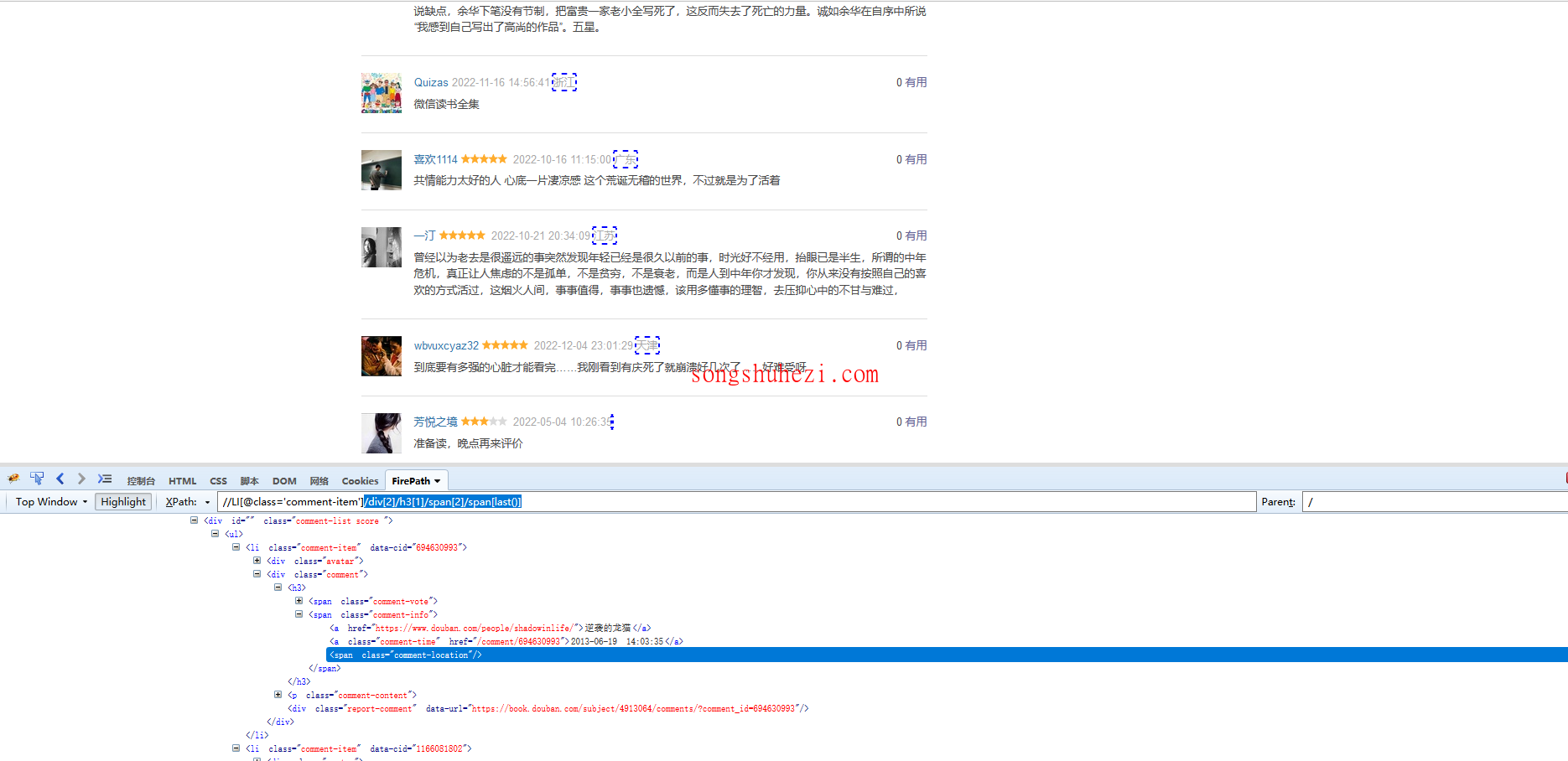
Step4:使用last()函数优化XPath
通过分析,我们发现所有的地区字段都在同一类标签内,并且是最后一个span标签。因此,我们可以利用last()函数来定位最后一个span元素。改进后的XPath是: //LI[@class='comment-item']/div[2]/h3[1]/span[2]/span[last()]。这个XPath可以正确定位所有的地区字段。
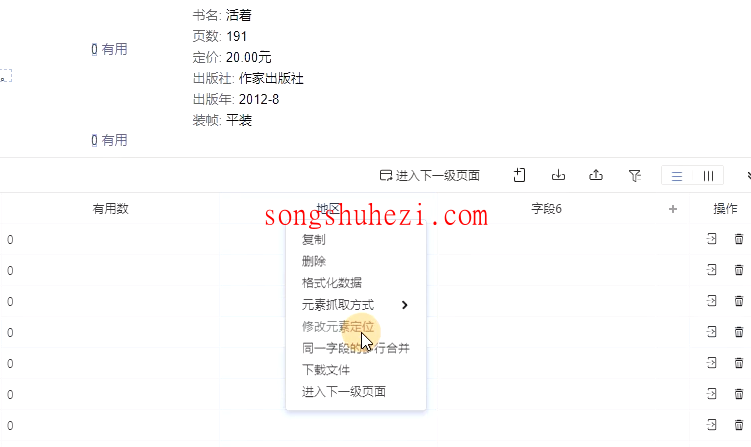
Step5:应用修改后的XPath
将新的XPath应用到采集工具中,我们就能准确地提取出所有评论的“地区”字段,数据也不会错位了。
结语
通过手动修改和优化XPath,我们能够解决采集过程中的字段提取问题,确保数据的准确性。虽然这种方法需要一定的XPath知识,但只要掌握了XPath的基础和相对XPath的使用,就能轻松应对这些问题。通过不断实践和优化XPath,我们能更好地应对不同类型的数据采集需求,让整个过程更加高效和精准。

反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS