






八爪鱼客户端自定义采集
当模板采集和自动识别采集都不能满足我们的需求时,如何更精确地抓取网页数据呢?这时,自定义采集功能就成了非常好的选择。自定义采集可以帮助我们根据自己的需求配置规则,提取特定的网页元素。今天,我就带你一步一步快速创建一个自定义采集案例,让你轻松搞定数据采集。
八爪鱼采集器官方链接:https://affiliate.bazhuayu.com/7hypDr
1. 输入网址
首先,进入采集工具的主页,在搜索框中输入你想要采集的网址。比如我们要采集豆瓣网站上的图书标题信息,输入的示例网址是:https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4。输入网址后,进入到采集页面。
在页面上,我们可以看到右侧会显示出一栏规则设置区域。此时,该区域里只有一个“打开网页”的规则,底部是数据预览区,但是因为我们还没有设置采集规则,所以数据预览区域是空的。
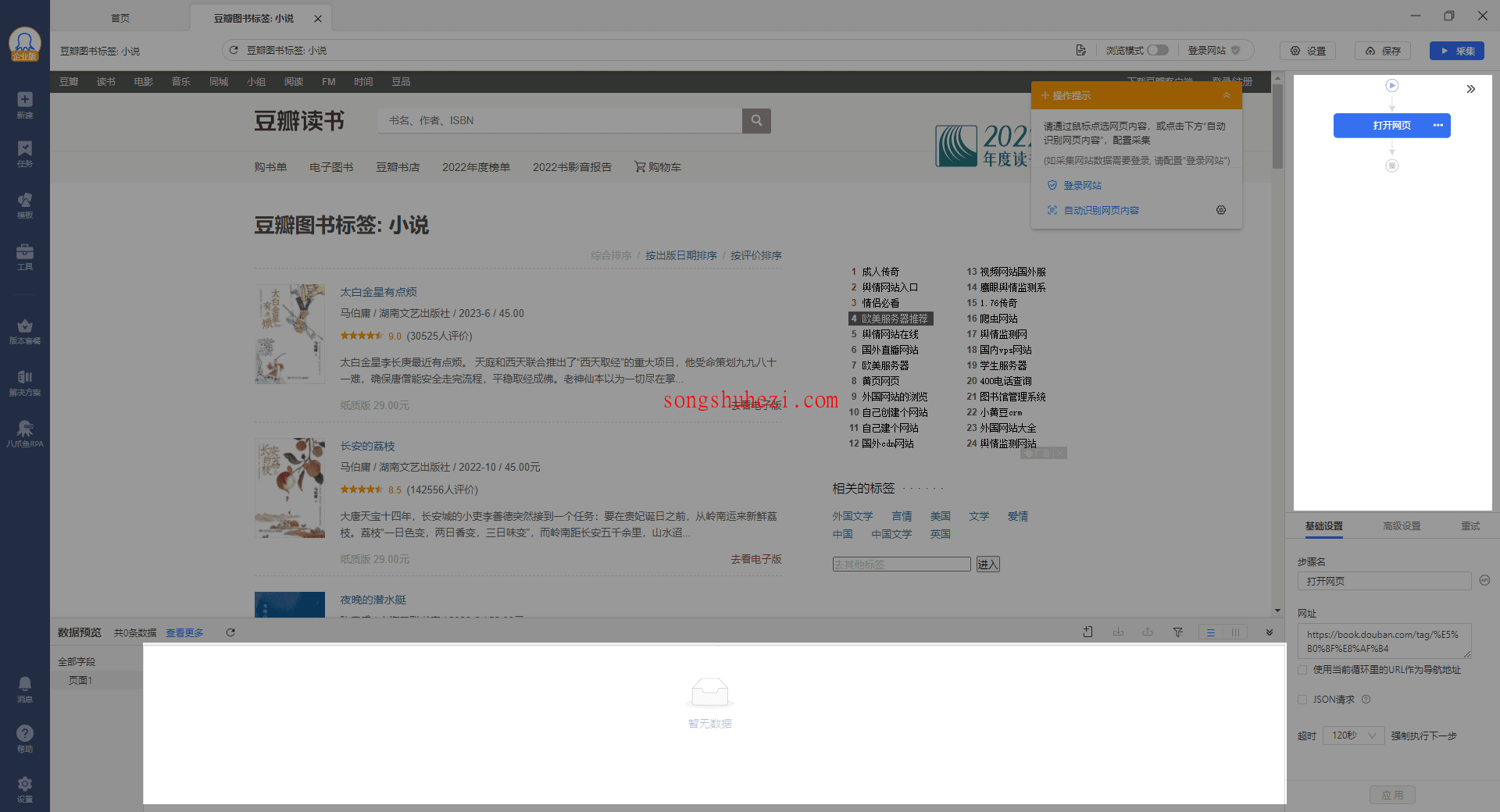
2. 选中要采集的元素并提取数据
接下来,我们要开始选择网页上的采集元素。比如在豆瓣图书页面,我们要采集的是图书的标题。点击网页中的图书标题,页面会自动高亮选中的标题,并且会显示出所有相似的标题,红色虚线标出。
这时,操作提示框会出现【提取数据】和【鼠标操作】两类操作选项。
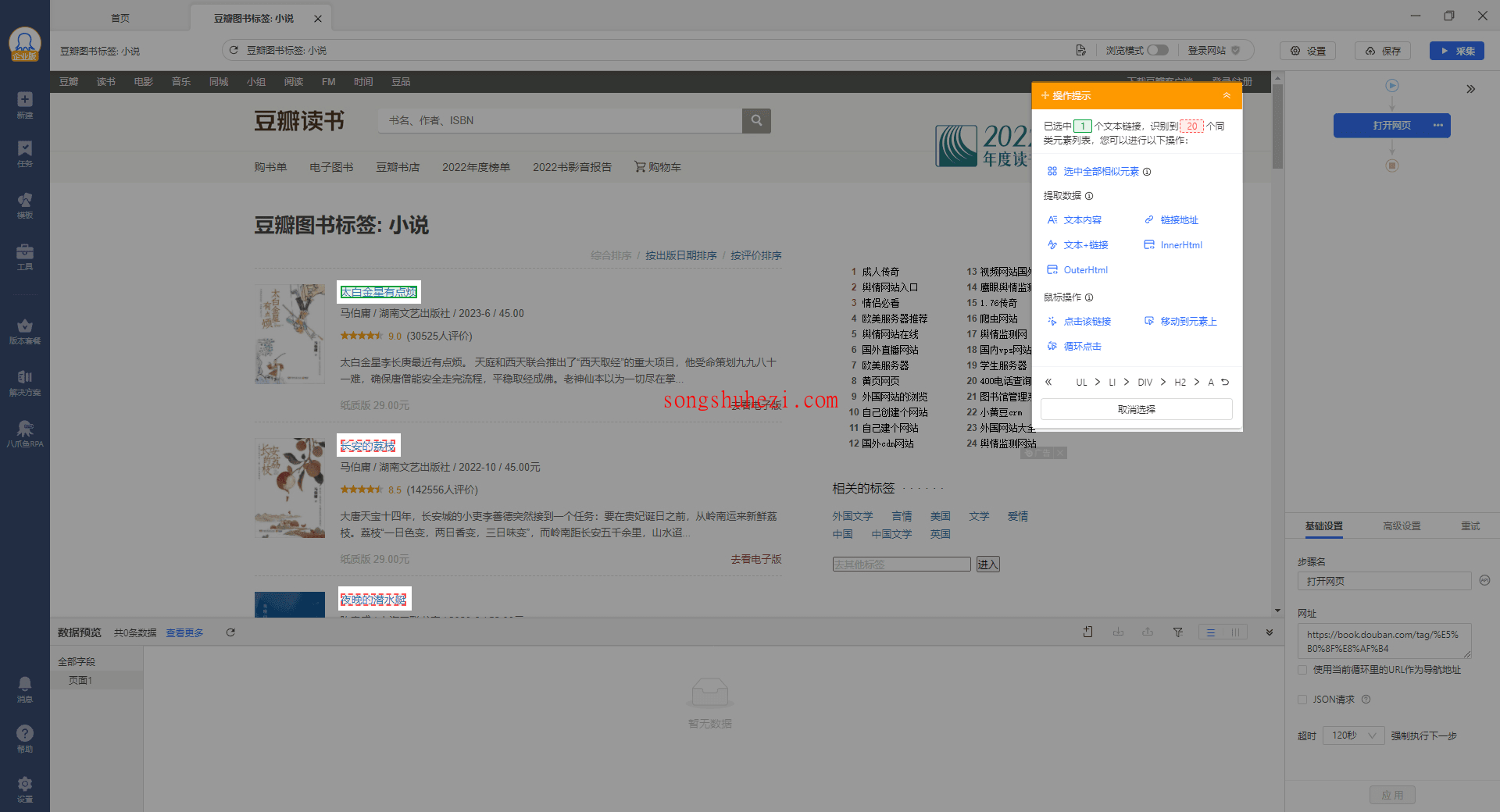
我们可以选择【选中全部相似元素】,这样页面中所有带红色虚线的标题都会变成绿色,表示它们已经被选中。同时,底部会出现绿色数据预选框,意味着我们已经成功选中了所有要采集的图书标题。
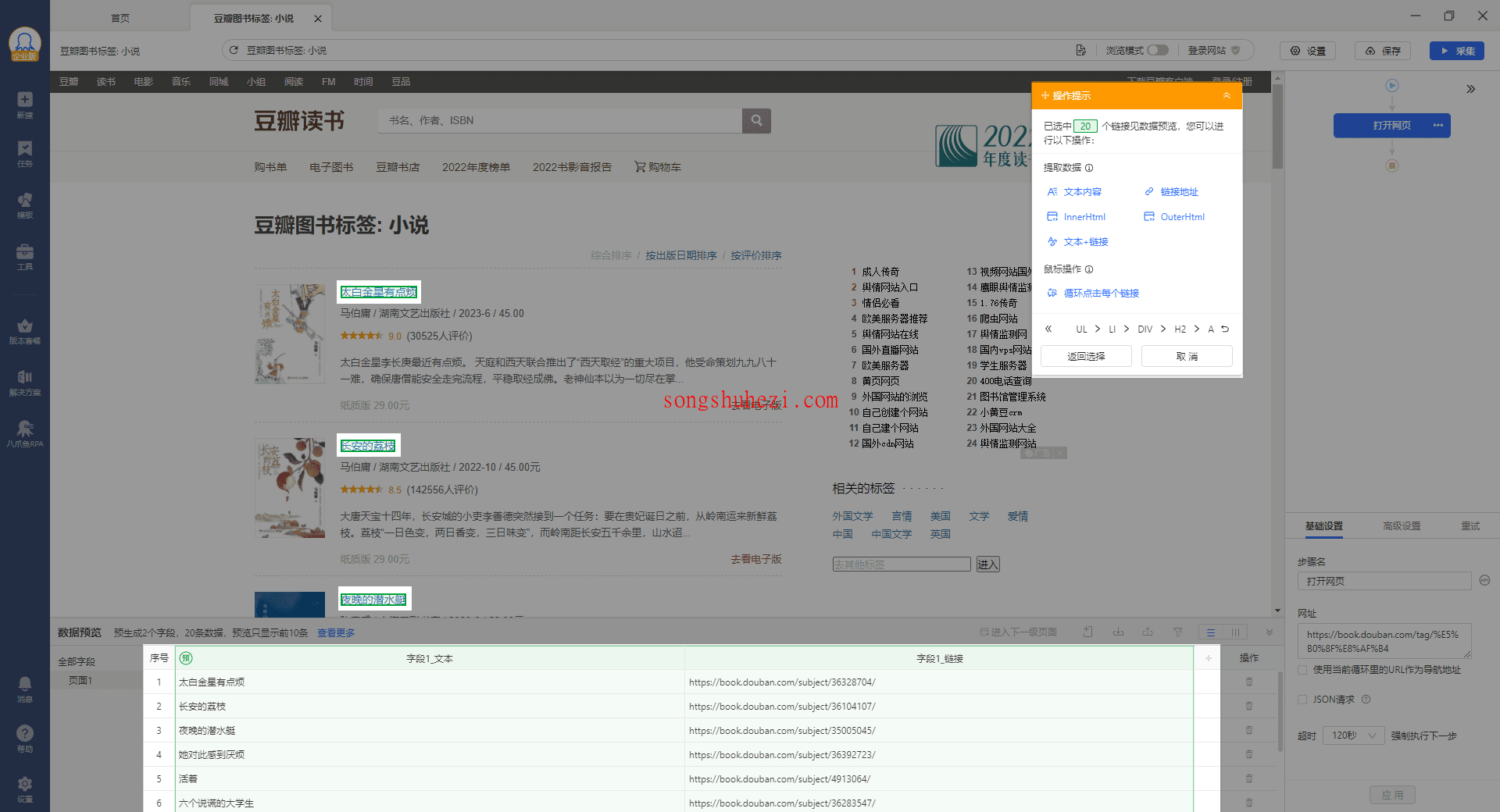
此时,页面会提示我们要选择采集数据的类型。由于图书标题是文本信息,因此我们选择【文本内容】。你会看到,原本的选中框消失了,底部的绿色预选框变为白色,表示我们已经成功选中了要采集的文本内容,并且右侧规则区域已经生成了相应的规则。操作提示框也提示我们是否需要翻页等操作,这里我们不需要翻页,只需要修改字段名称然后点击采集。

3. 修改字段名称
此时,已经选中了所有需要采集的数据元素。为了让数据更有意义,我们可以修改字段名称。在提取的数据列表中,双击字段名,将它修改为更合适的名称,比如“图书名”。
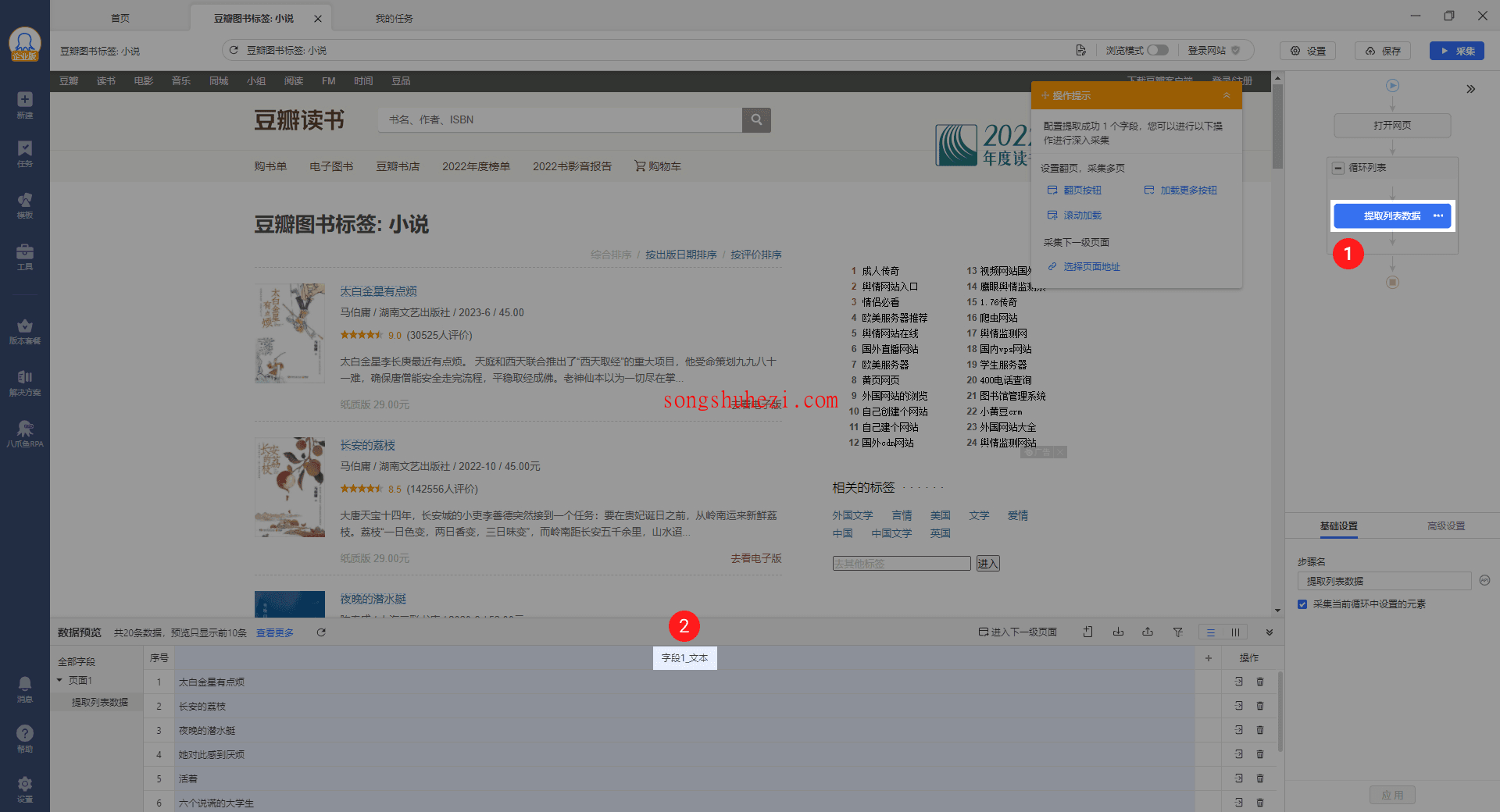
这一步虽然简单,但能让后期的数据导出和分析变得更清晰易懂。
4. 启动采集
字段名称修改完后,点击右上角的【采集】按钮,采集过程就会开始了。
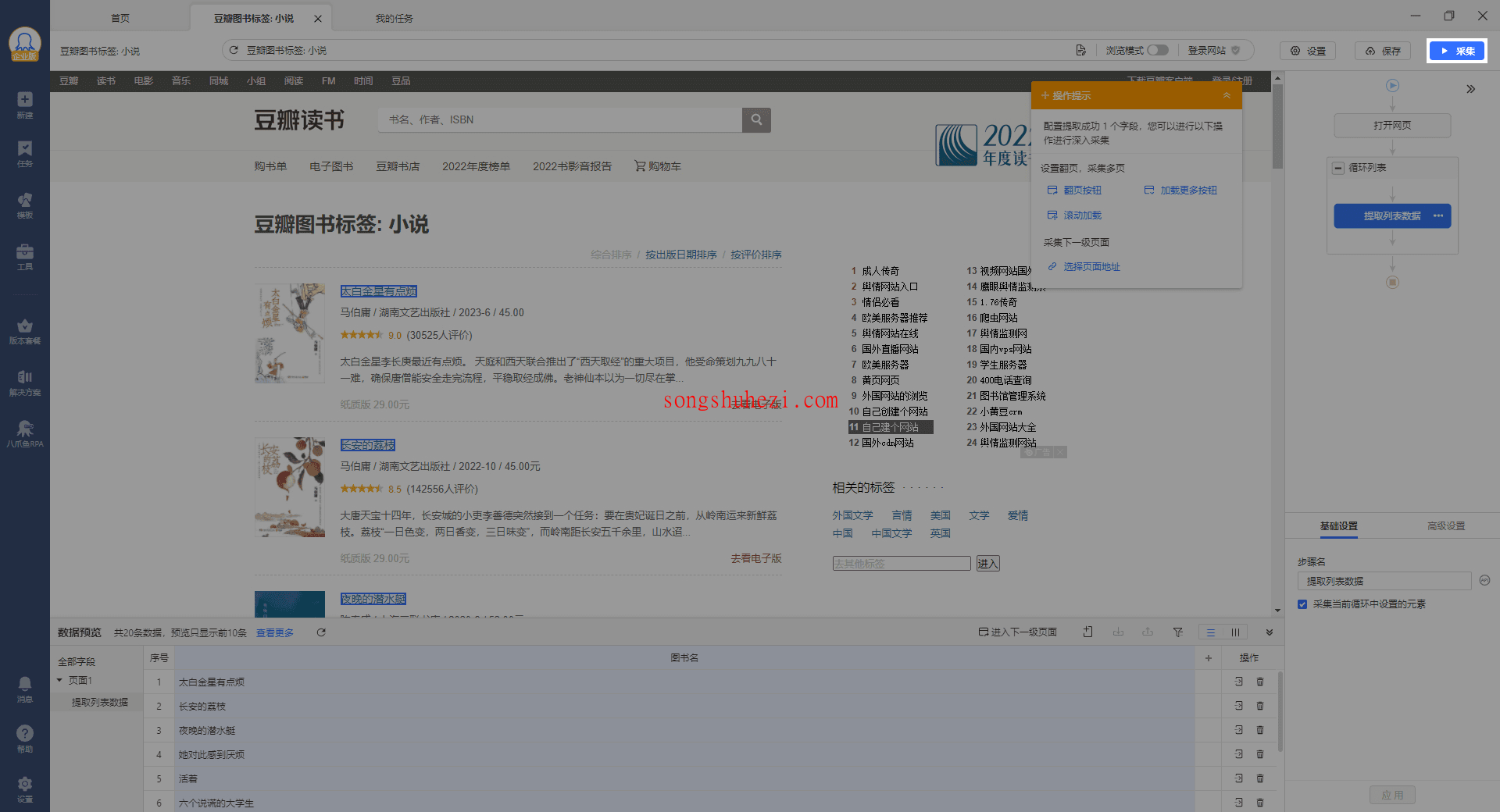
系统会根据我们配置的规则,开始从网页上抓取图书标题数据。你可以在页面上实时查看采集进度,确保采集过程顺利进行。
5. 导出数据
当采集完成后,你可以选择将数据导出到本地或直接保存到数据库。
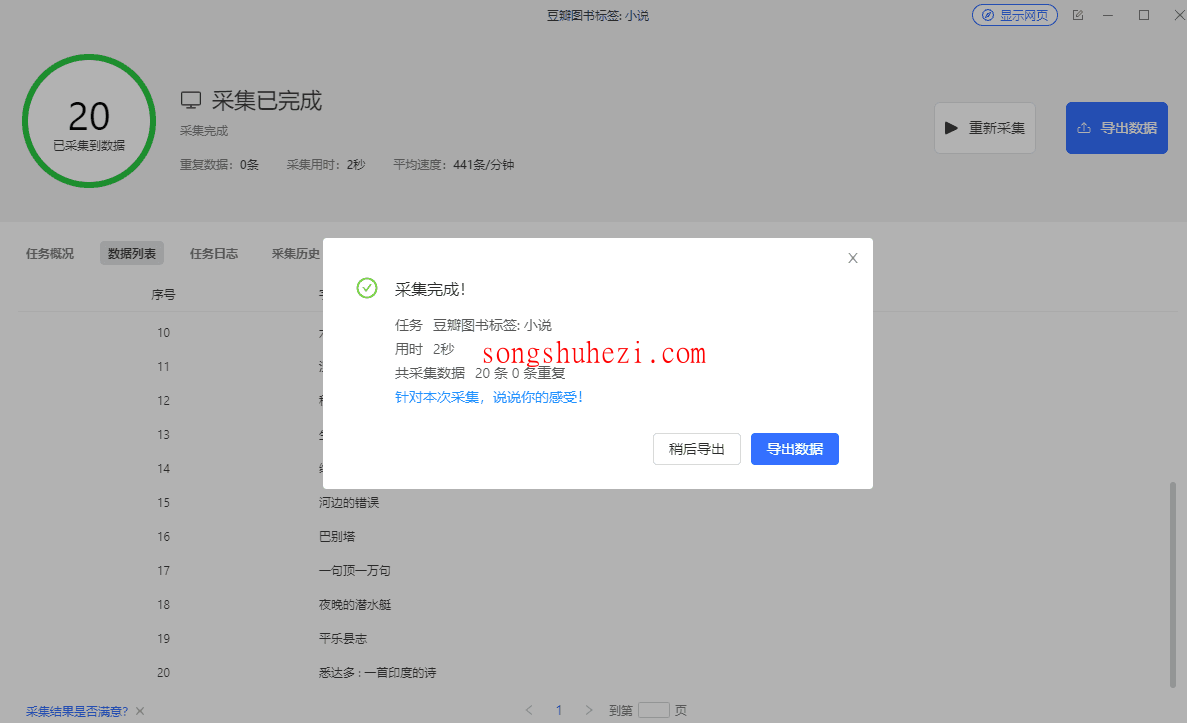
点击【停止】后,会弹出导出选项,选择导出数据的格式(如CSV、Excel等)。
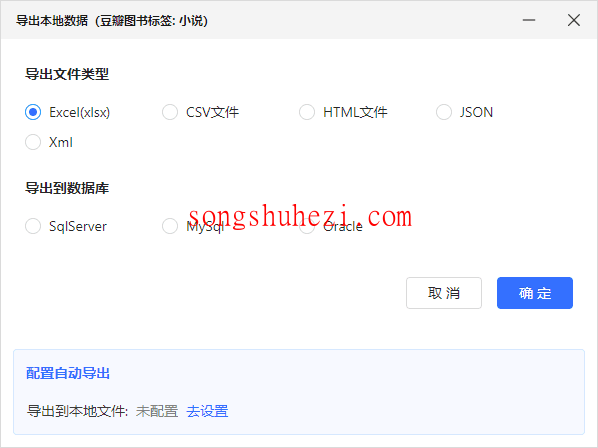
选择好格式后,点击导出,就可以成功下载采集到的数据了。打开导出的文件,你会看到完整的图书标题列表,所有数据已经按我们预设的规则成功提取出来。

我的体验
通过这次自定义采集,我发现其实操作并不复杂,步骤很清晰。特别是在选择采集元素时,系统会自动识别出相似的元素并高亮显示,操作非常直观。而且修改字段名称这一步也很重要,它让最终导出的数据更符合我们的需求。整体体验非常顺畅,我相信通过这个过程,你也能够轻松完成自定义采集,抓取自己需要的网页数据。
总的来说,自定义采集是一项非常灵活且高效的工具,适合那些需要精准提取网页特定数据的场景。你只需配置简单的采集规则,就能抓取到想要的所有数据。试试看,相信你会觉得它非常好用!

反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS