






八爪鱼客户端自动识别采集
在日常的网页数据采集过程中,有时模板提供的配置无法满足我们的需求,怎么办呢?其实,我们可以通过智能识别采集来轻松解决这个问题。智能识别采集不仅简单易用,而且快速高效,适合各种数据采集场景。那么,今天我就来为大家详细介绍如何使用这一智能识别功能。
八爪鱼采集器官方链接:https://affiliate.bazhuayu.com/7hypDr
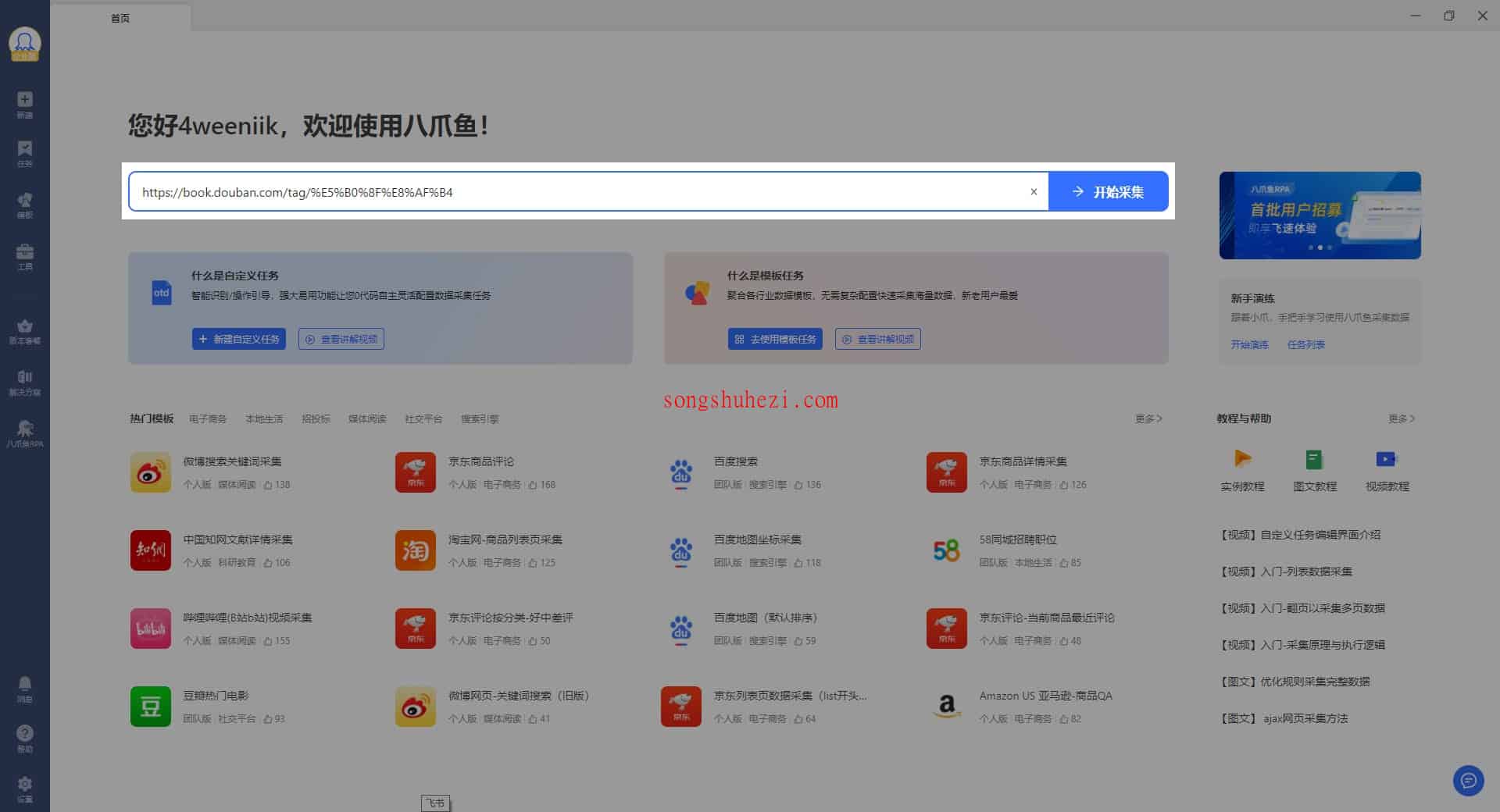
1. 输入网址
首先,进入到采集工具的主页,在搜索框中输入你要采集的网址。
比如,想要采集豆瓣书籍标签的内容,你可以输入以下示例网址:https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4。这个步骤非常简单,只要确认网址正确,系统就能快速定位页面内容。
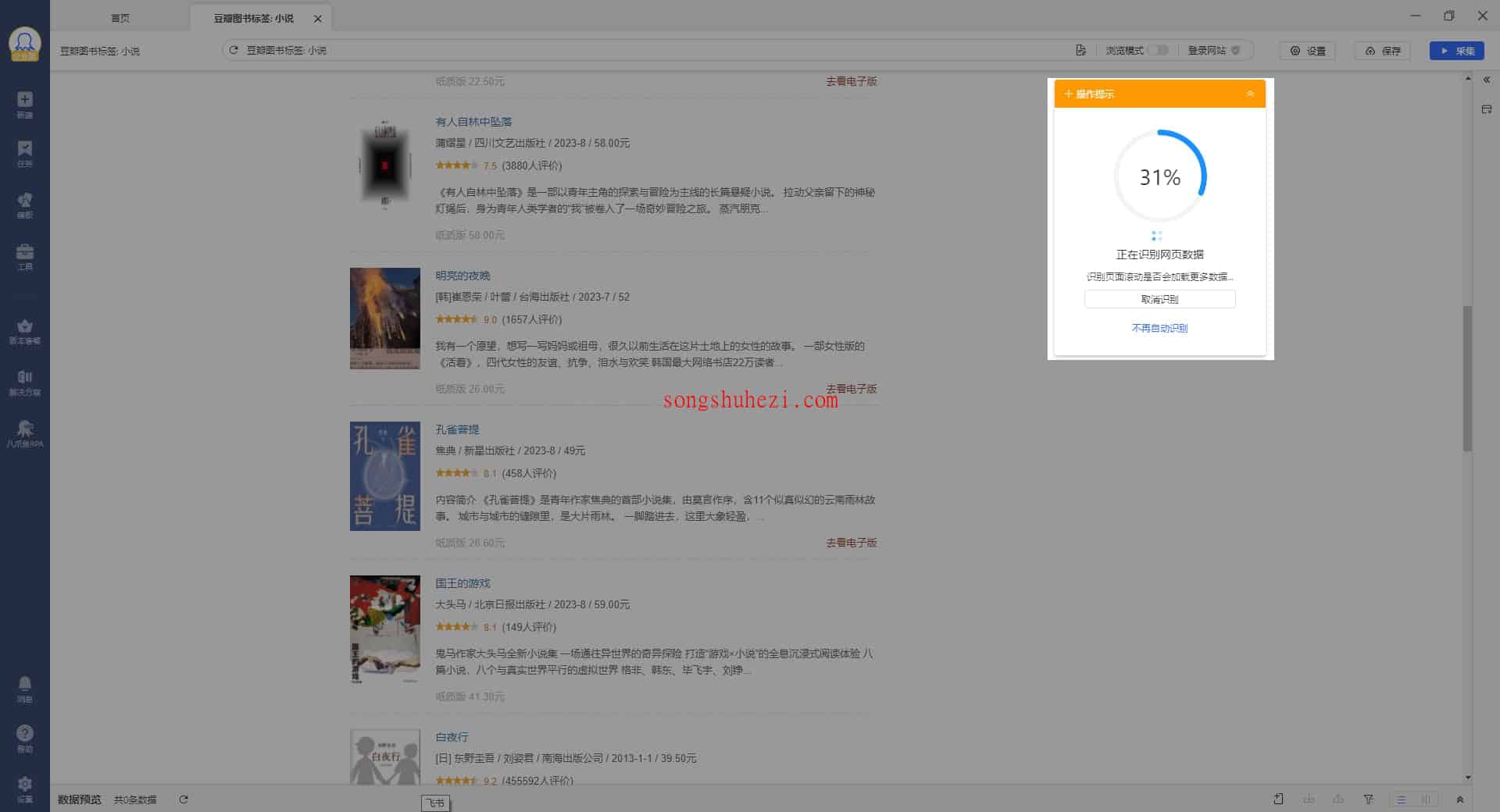
2. 点击【自动识别网页内容】
进入到自定义编辑页面后,你会看到页面右上方有一个黄色边框的提示框,里面写着【自动识别网页内容】。

只需要点击这个按钮,系统就会自动开始识别网页数据,并为你配置好相应的采集规则。
3. 生成采集设置
系统完成自动识别后,会生成一些预设的采集规则。接下来,你可以检查页面底部的数据字段,确保它们与自己的预期一致。如果不太符合要求,别担心,你可以选择【切换识别结果】来调整采集的字段。确认好采集字段后,点击【生成采集设置】按钮。
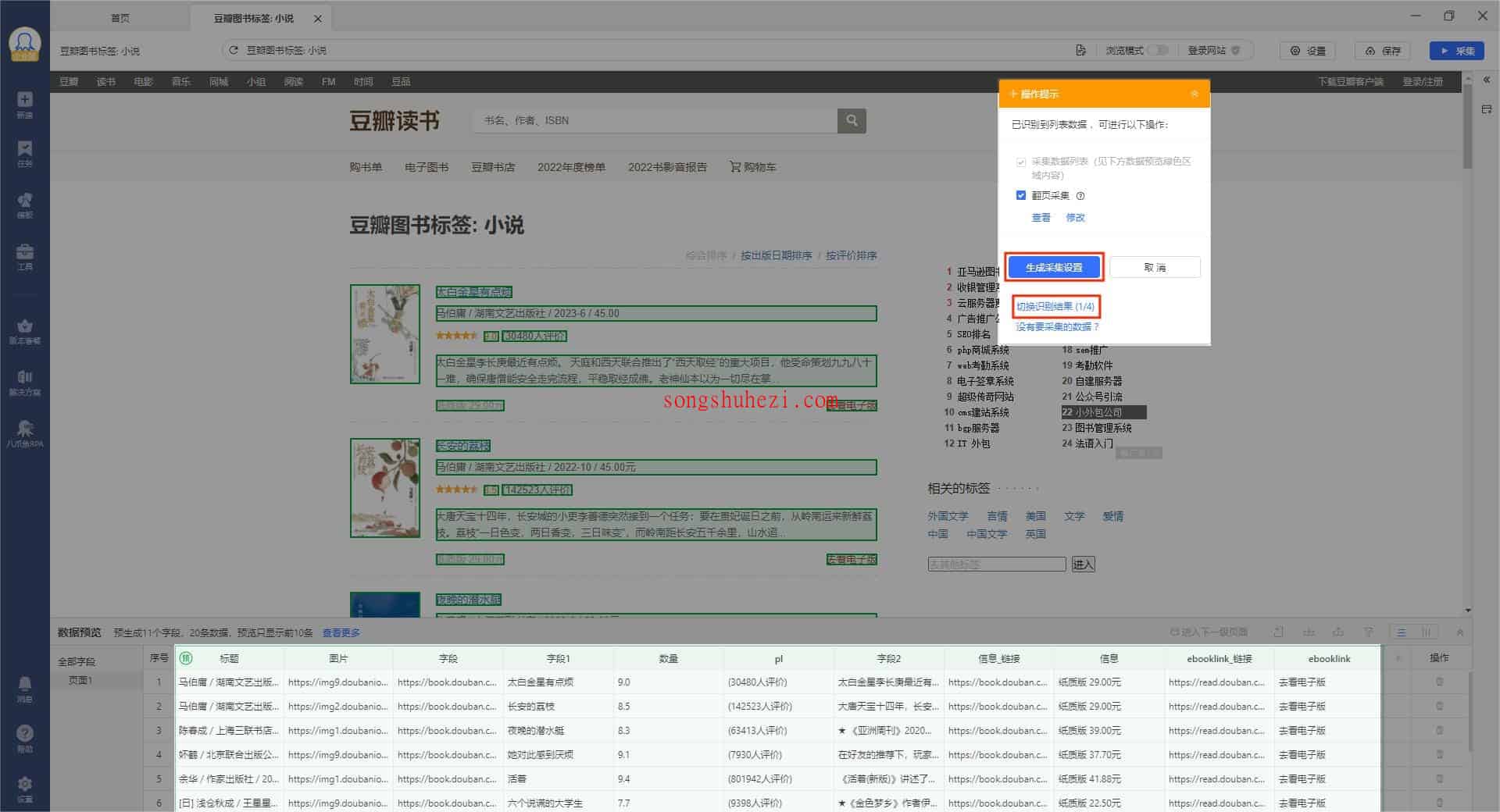
此时,你可以看到客户端右侧展示出采集规则,并且底部的绿色预选字段也会变为白色,表明采集设置已经准备完毕。
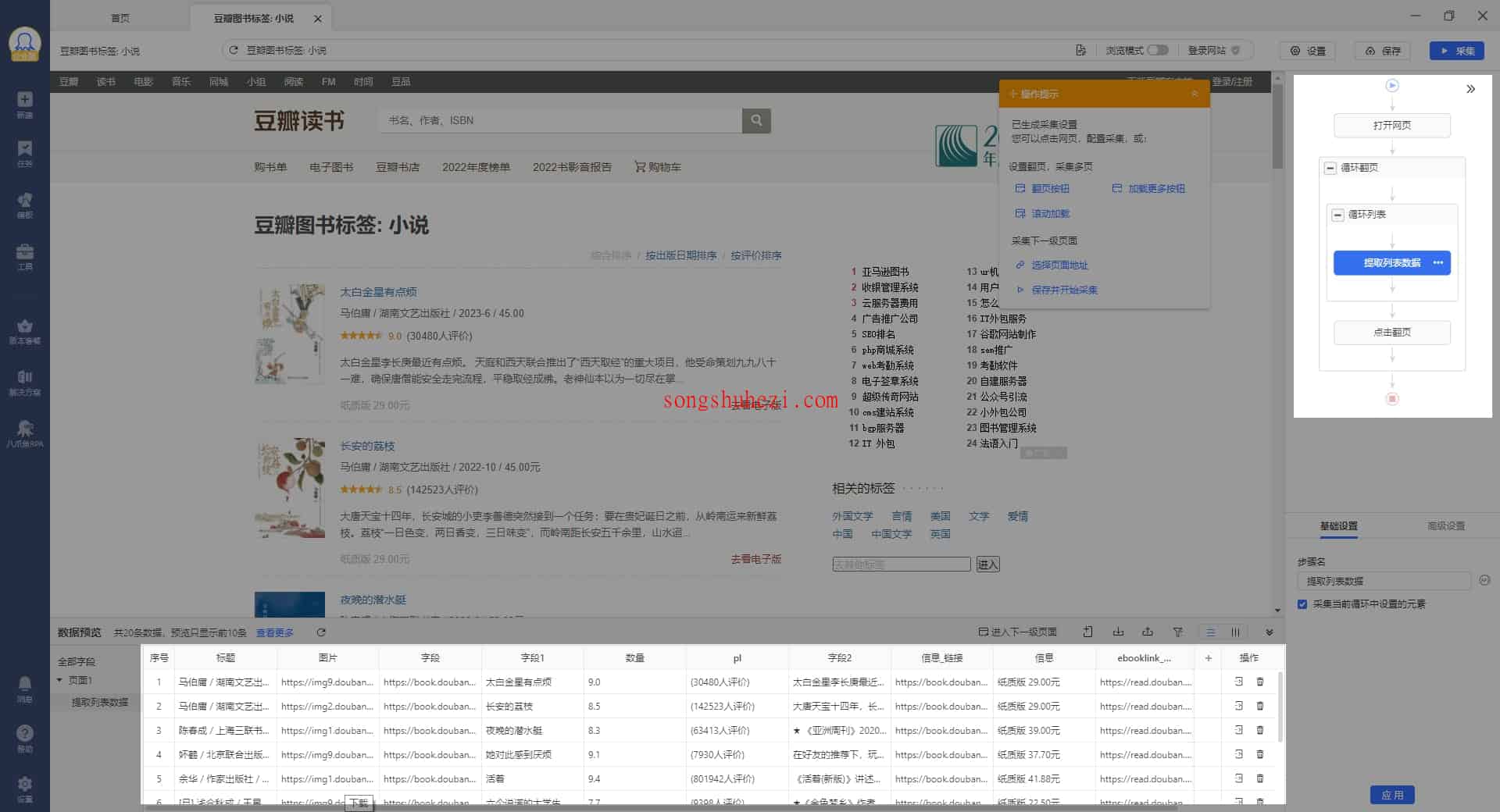
4. 启动采集
当采集设置完成后,点击【启动采集】按钮,就可以开始采集数据了。
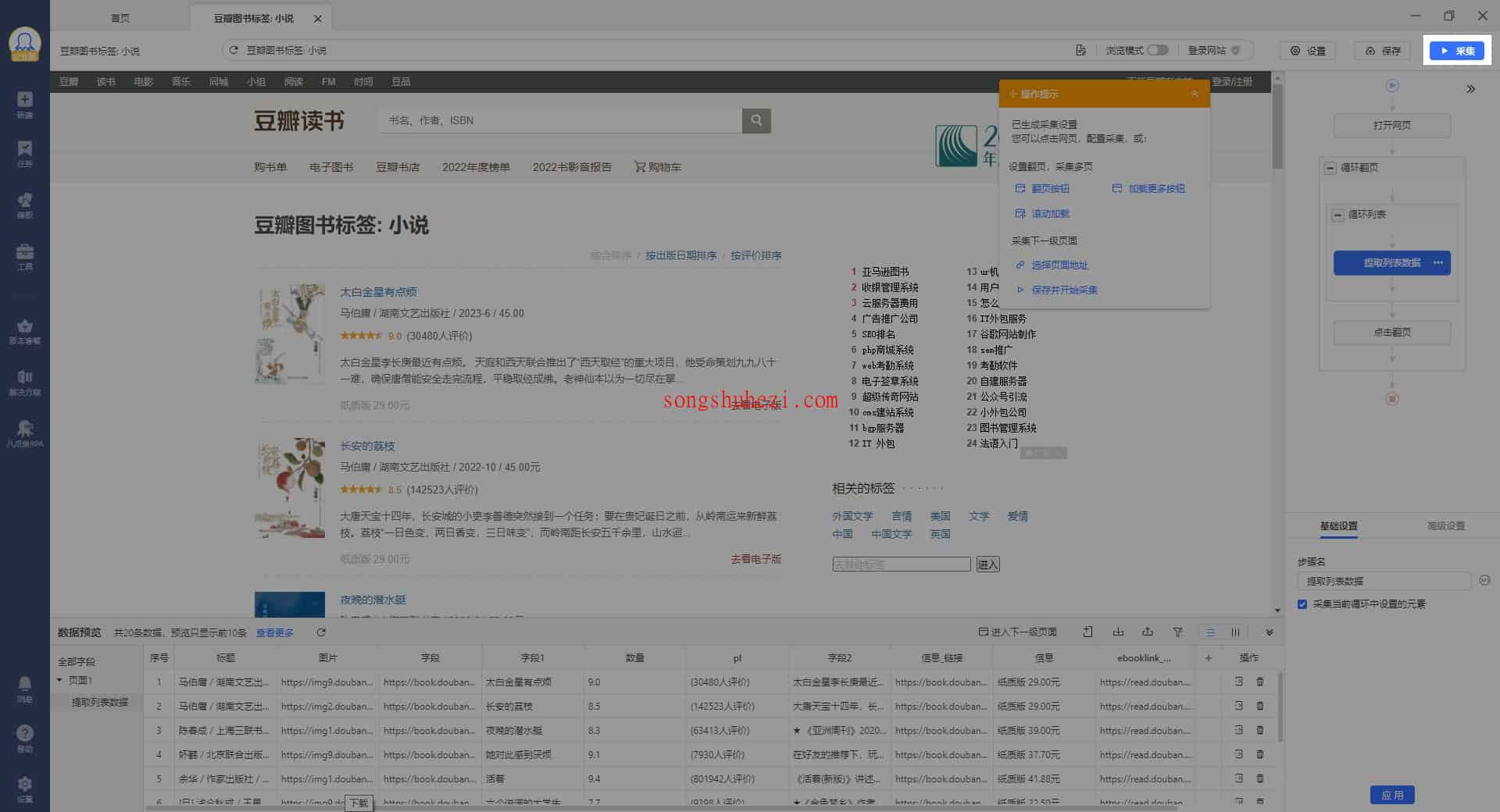
在启动采集前,你需要选择采集方式,可以选择“本地采集”或者“云采集”。
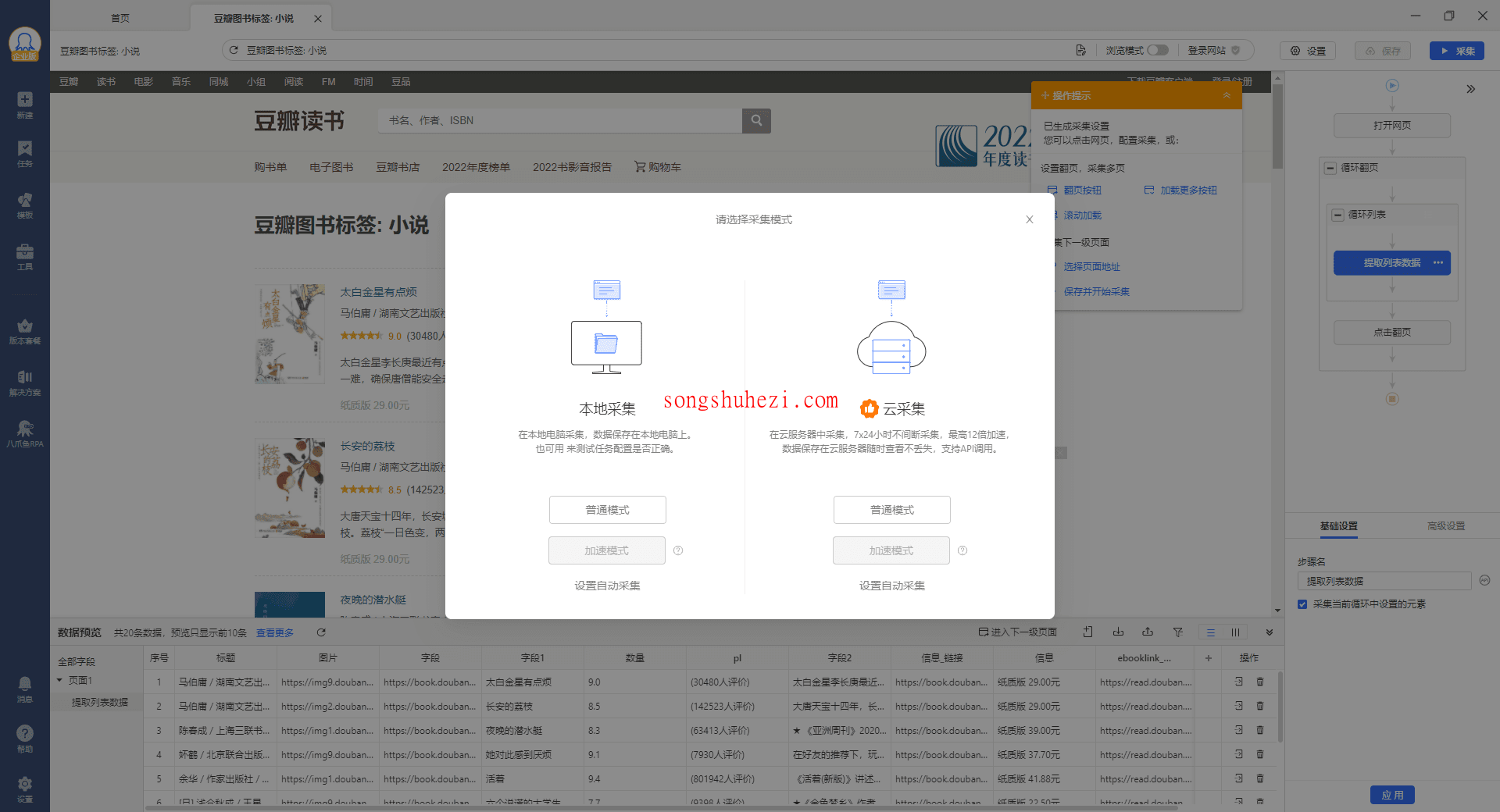
这里我们选择“本地采集”的普通模式。
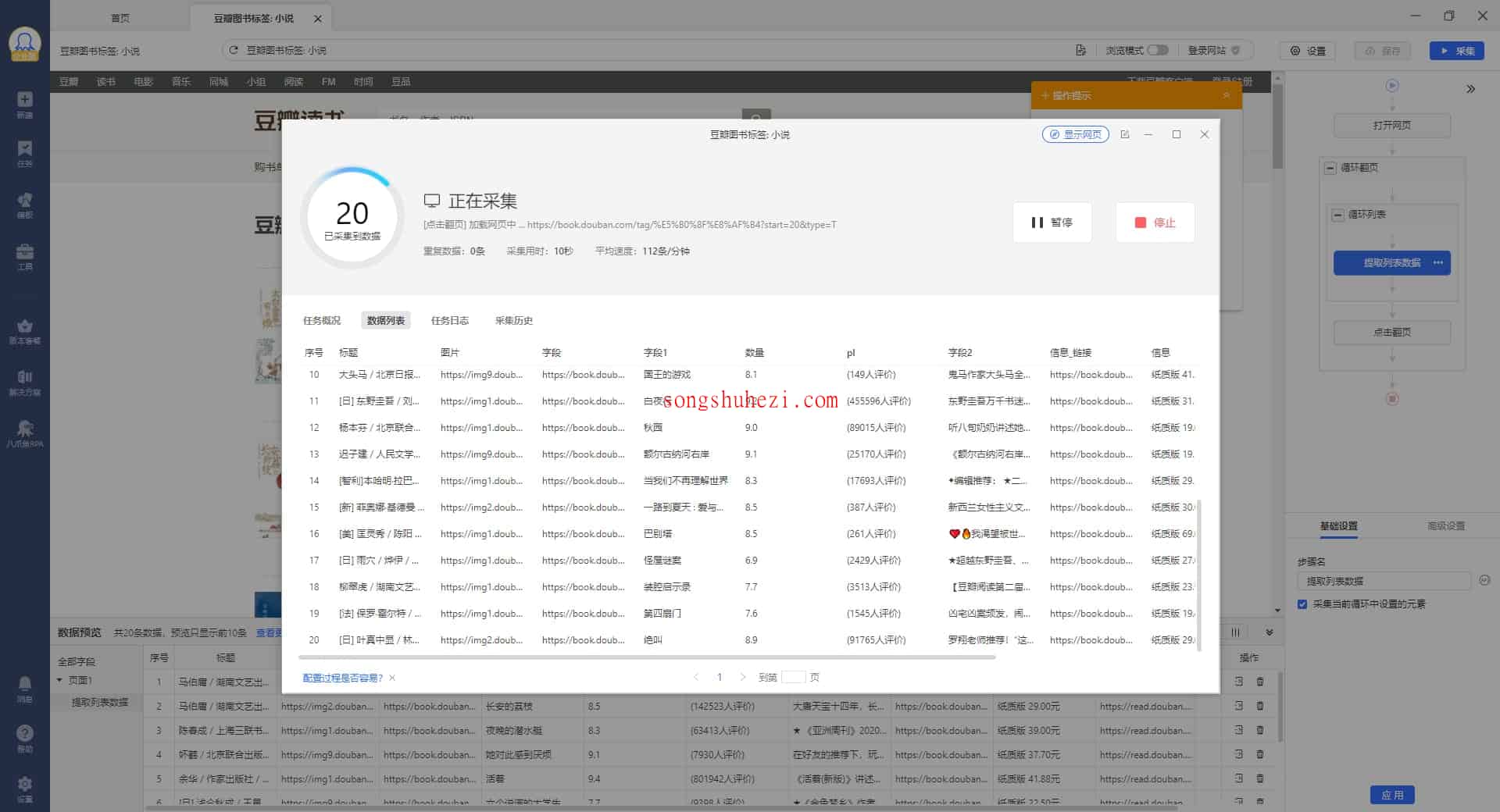
选择完毕后,系统将开始采集网页上的数据,并在页面上展示采集结果,你可以随时查看是否采集成功。
5. 导出数据
数据采集完成后,点击【停止】按钮,系统会提供数据导出的选项。
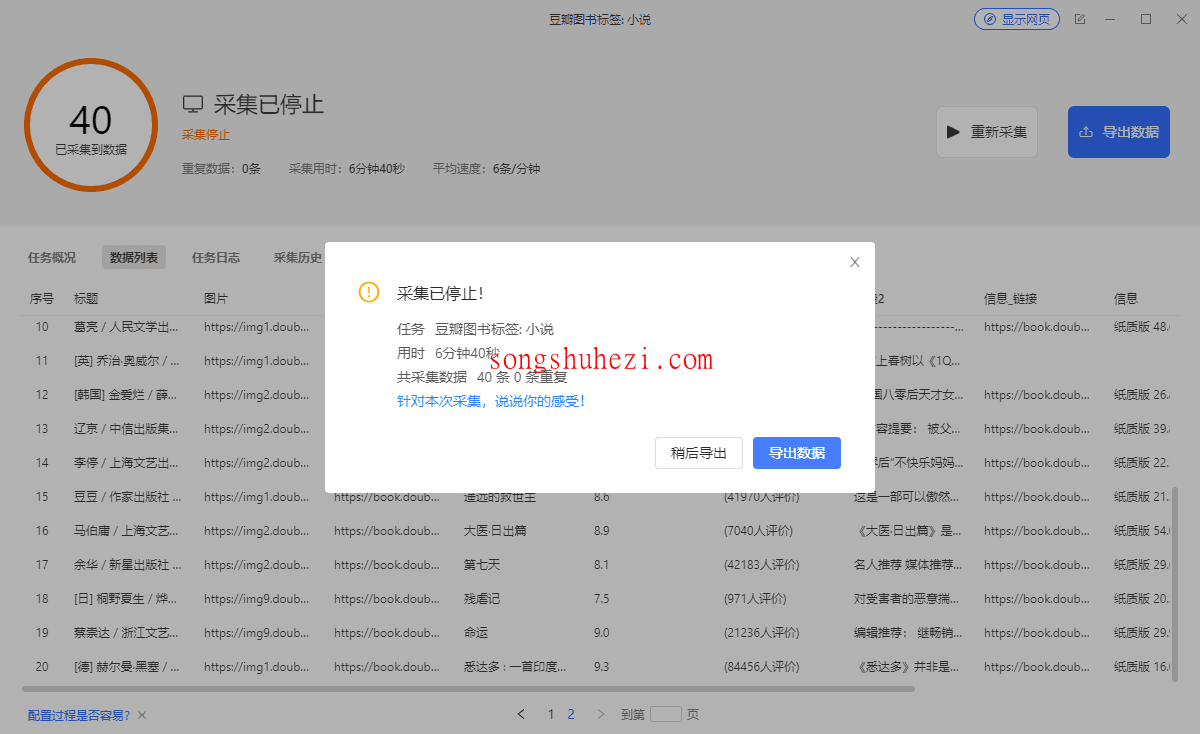
你可以选择导出数据的格式,根据需要导出成CSV、Excel等格式。

导出完毕,你就成功获取到了所需的数据!这样,整个采集过程就完成了,真的是既简单又高效!

我的体验
通过使用智能识别采集工具,我发现它在处理复杂网页内容时特别有用。尤其是当网页结构比较复杂,传统模板无法完全适应时,智能识别就能快速帮你识别出需要的数据字段,省去了大量手动设置的时间。而且,整个过程都很直观,按照步骤操作就可以完成采集,真的很方便。
总结一下,智能识别采集是一项非常实用的功能,特别适合那些需要快速抓取网页数据的场景。无论是简单的文本内容,还是复杂的网页结构,它都能有效应对,节省了大量的时间和精力。如果你也有类似的采集需求,不妨试试看智能识别采集,绝对会让你事半功倍!

反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS