






八爪鱼如何进行百度爱采购厂家信息采集教程
大家平时刷微博的时候,是不是经常想找某个话题下的热门博文?尤其是做舆情分析、市场调研、写论文的时候,手动去扒数据真的费时又费力!不过呢,最近我发现用八爪鱼来采集微博搜索结果,效率简直起飞了,想采多少就采多少,还能一键导出成Excel,超方便!
八爪鱼采集器官方链接:https://affiliate.bazhuayu.com/7hypDr
今天就来跟大家聊聊,怎么用八爪鱼一步步搞定微博搜索内容采集,保姆级教程,不懂技术也能学会哈!
第一步,打开微博首页
首先嘛,打开八爪鱼软件,在首页搜索框输入微博的网址:https://weibo.com/,然后点击【开始采集】,它会自动帮你打开微博页面,超级方便。
不过啊,注意点一下弹出来的【取消识别】,因为这时候我们还不需要让它帮忙识别页面内容。
第二步,登录微博
要想采集微博上的内容,必须登录账号!否则最多只能采一页的数据,太鸡肋了。
这里推荐用Cookie的方式登录:
- 在八爪鱼里点【浏览器模式】,像平时用浏览器一样,扫码登录自己的微博。
- 登录成功后,去【打开网页】设置那里勾选【使用指定的Cookie】,然后点【获取当前页面Cookie】,保存就好啦!

这样设置好,后面每次启动采集都是直接登录好的状态,再也不用重复扫码啦,超省心!
第三步,设置高级搜索条件
微博搜索是支持高级搜索的,比如筛原创、按时间范围搜索,或者只找带图的博文,这些都可以提前设置好。
这里推荐用偷懒的办法哈:
- 在浏览器里手动输入关键词,比如【三体】,打开【高级搜索】选好条件,比如【原创】【指定时间段】。
- 搜索后,把浏览器地址栏的完整网址复制下来备用。
- 回到八爪鱼,在【打开网页】步骤里新增一个【打开网页1】,直接粘这个网址进去。
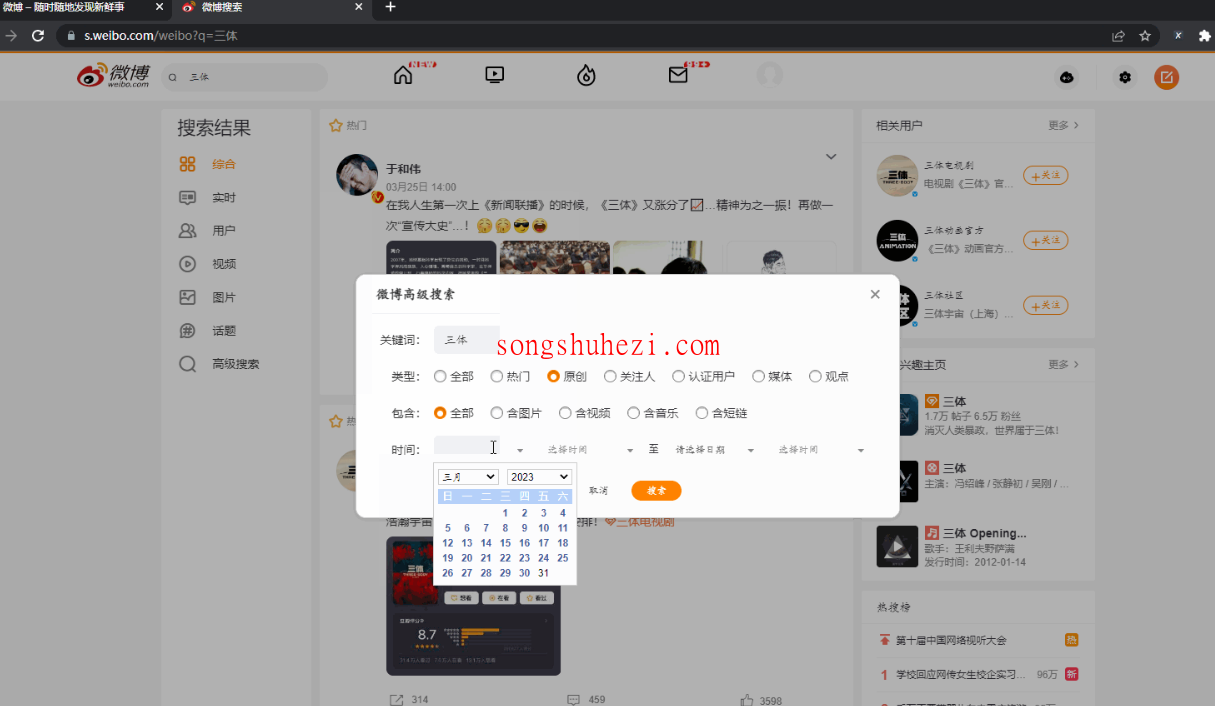
这样就能直接进入带筛选条件的搜索结果页啦,既快又准!
第四步,自动识别列表页和翻页
网页打开后,直接点【自动识别网页内容】,稍等几秒,它就能识别出博文列表和翻页按钮了。
点【生成采集设置】,让八爪鱼自动搭建好整个流程。
不过呢,自动识别有时候不够精准,需要手动调整一下XPath:
【循环翻页】改成:
//a[contains(text(),'下一页')]【循环列表1】改成:
//div[@class="card-wrap" and @mid]
这两步超重要,关系到能不能采全数据哦!
第五步,编辑字段
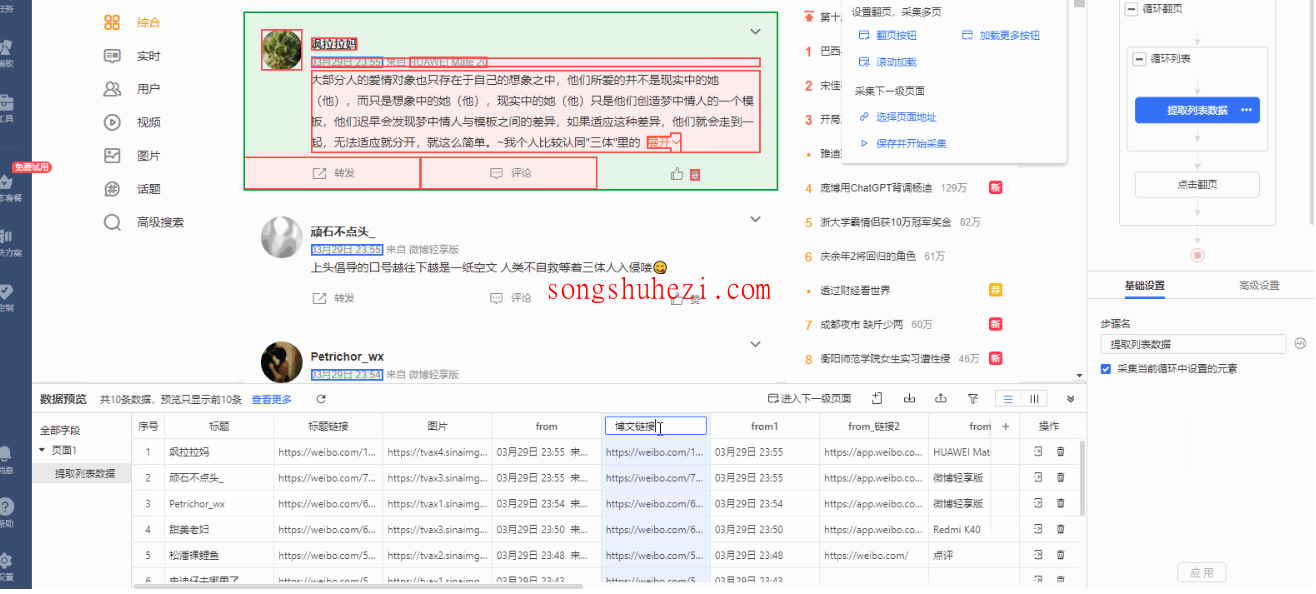
在【当前页面数据预览】面板那里,可以看到八爪鱼默认采集的一堆字段。
这时候可以删掉没用的字段,改字段名字,比如把“内容”改成“博文内容”,让表格导出来更清晰。
还可以自己手动加字段,比如评论时间、评论用户名什么的,都能一网打尽。
第六步,优化字段提取
有几个字段需要特别优化一下,不然提取出来的数据会不完整或者不好用:
博文内容
默认的提取规则,只能抓到没展开的短博文。要想采到完整长博文,记得把XPath改成:
//div[@class="content"]//*[@class='txt'][last()]转发数、评论数、点赞数
这些数量默认是带“转发”“评论”“赞”字样的,不够干净。
想只保留数字的话,点字段右上角【...】,选【格式化数据】→【正则表达式匹配】,填【\d+】,保存就好。
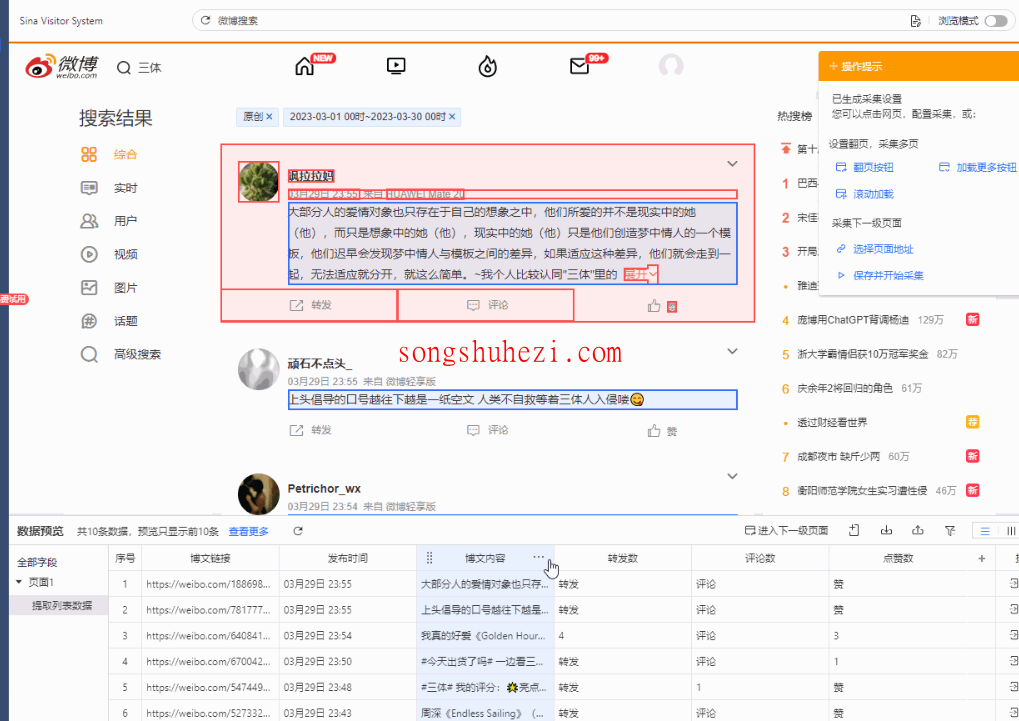
处理完这些小细节,数据就又干净又完整啦!
第七步,采集多个关键词的搜索结果
如果只采一个关键词太单调了,想要采一堆关键词怎么办?八爪鱼也能轻松搞定!
方法是这样的:
在【打开网页】后,加一个【循环】。
循环方式选【网址列表】,然后【批量生成】网址。
把之前复制的搜索结果网址拿出来,删掉关键词参数部分,插入【自定义列表】,输入你想采的多个关键词。
设置好后,八爪鱼就能自动换关键词去搜,超智能!
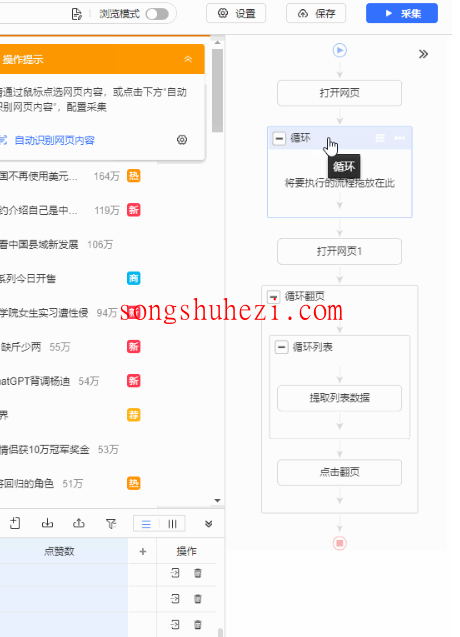
调整一下流程结构,让【打开网页1】和【翻页循环】都拖进【循环】里,完美搞定。
第八步,启动采集
最后嘛,点【采集】按钮,然后选【启动本地采集】。
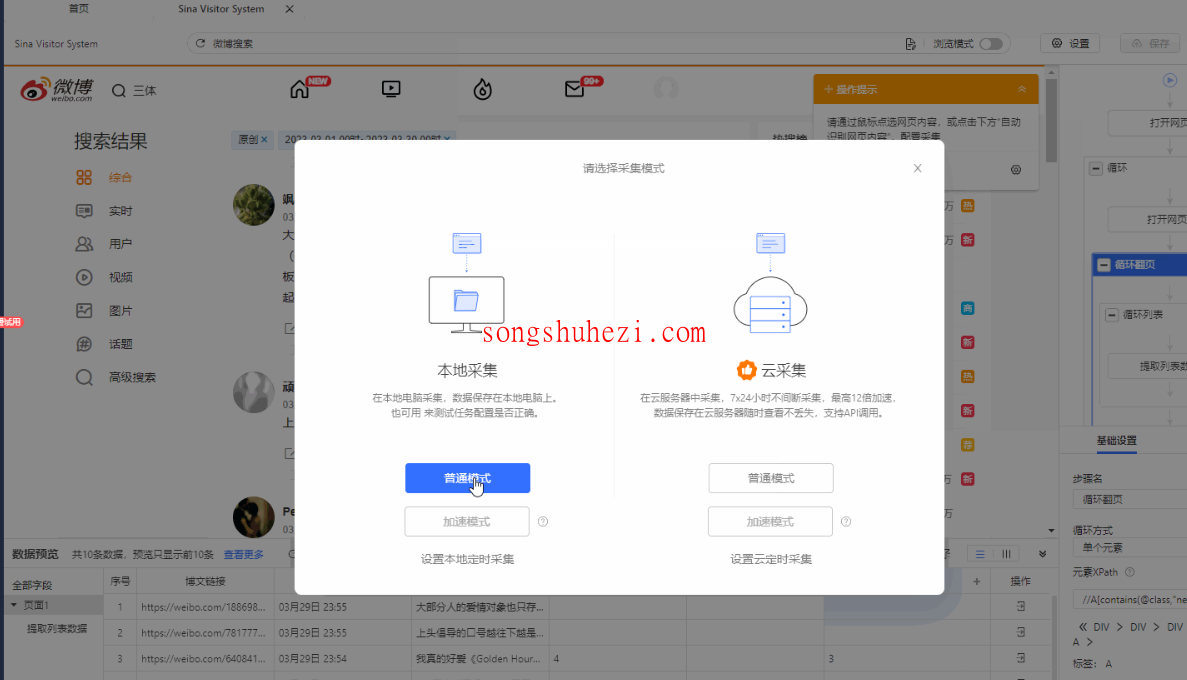
八爪鱼就开始一条条扒数据了,你可以一边喝奶茶一边等着它搞定,超级省力!
数据采完后,想导出成什么格式随便选,Excel、CSV、HTML、数据库通通支持。我自己一般都是直接导出Excel,清清爽爽,后续做分析处理特别方便。
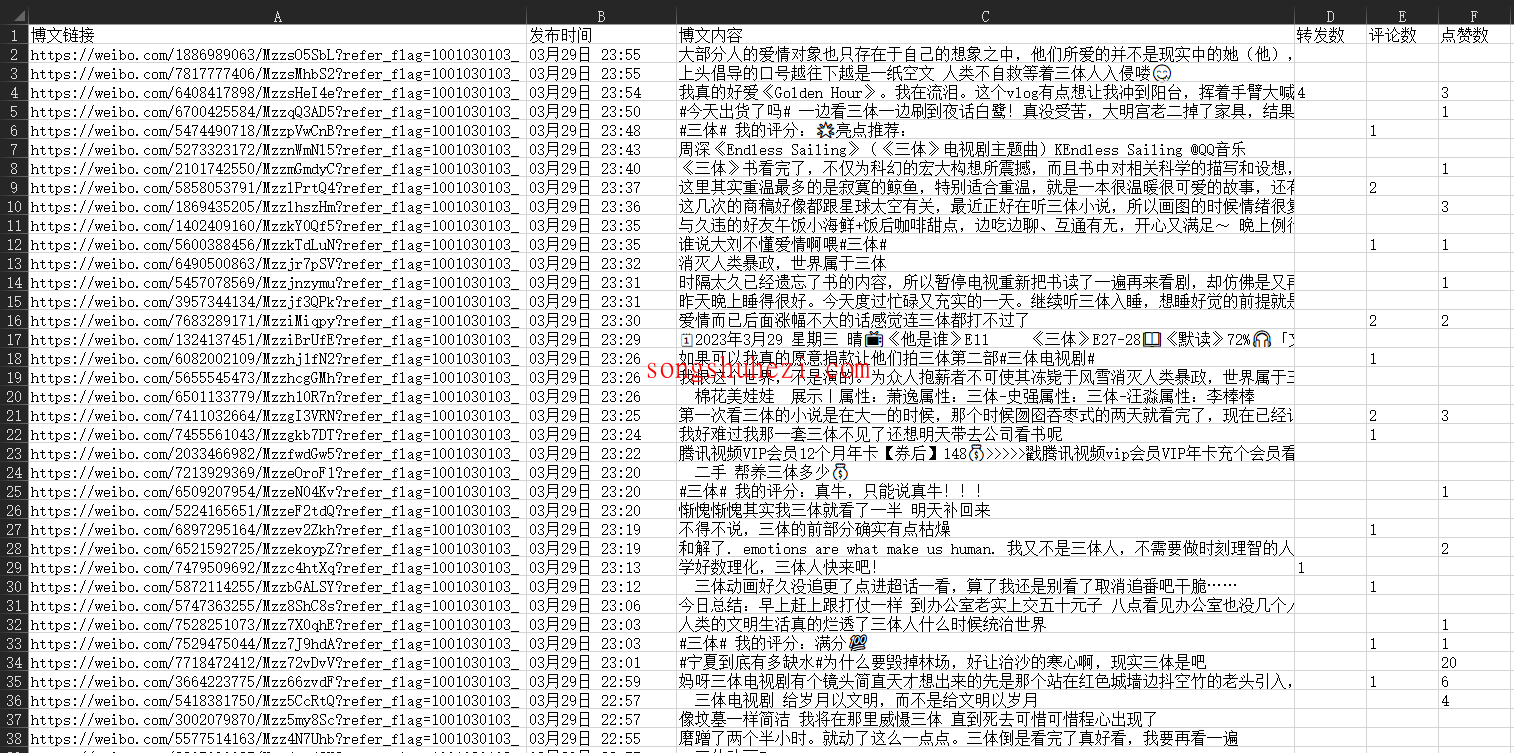
我的感觉是,用八爪鱼搞微博搜索数据采集,真的是事半功倍。以前靠手扒一个话题几百条微博,搞到怀疑人生。现在直接批量跑,一下午能搞定好几万个数据,效率爆炸高!
如果你也有社交舆情分析、市场调查、学术研究这方面的需求,八爪鱼真的可以大胆安排上了,超级香!

反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS