






八爪鱼采集列表工具
大家平时是不是经常在网上浏览各种商品列表、书籍列表,或者是其他类型的列表数据?你有没有想过,如何将这些数据收集到自己的电脑里,方便做分析或整理呢?今天就来跟大家分享一下,如何使用八爪鱼这款强大的网页数据抓取工具,采集列表数据。
八爪鱼采集器官方链接:https://affiliate.bazhuayu.com/7hypDr
八爪鱼可以通过简单配置,帮助你自动抓取网页上所有的结构相同的列表内容。例如,你想采集豆瓣图书列表中的书籍信息,包括书名、评分、出版信息等,八爪鱼就能帮助你轻松实现。接下来,我们来看看具体操作步骤。
如何使用八爪鱼采集列表数据
一、智能识别
首先,八爪鱼有一个非常智能的识别功能。你只需要输入目标网址,八爪鱼会自动识别网页内容,并生成相应的采集流程。这种方式非常适合初学者,省去了很多复杂的配置步骤。
二、自行配置采集流程
如果你想更细致地控制采集的内容,可以选择自行配置采集流程。下面我们就来看一下具体的操作步骤。
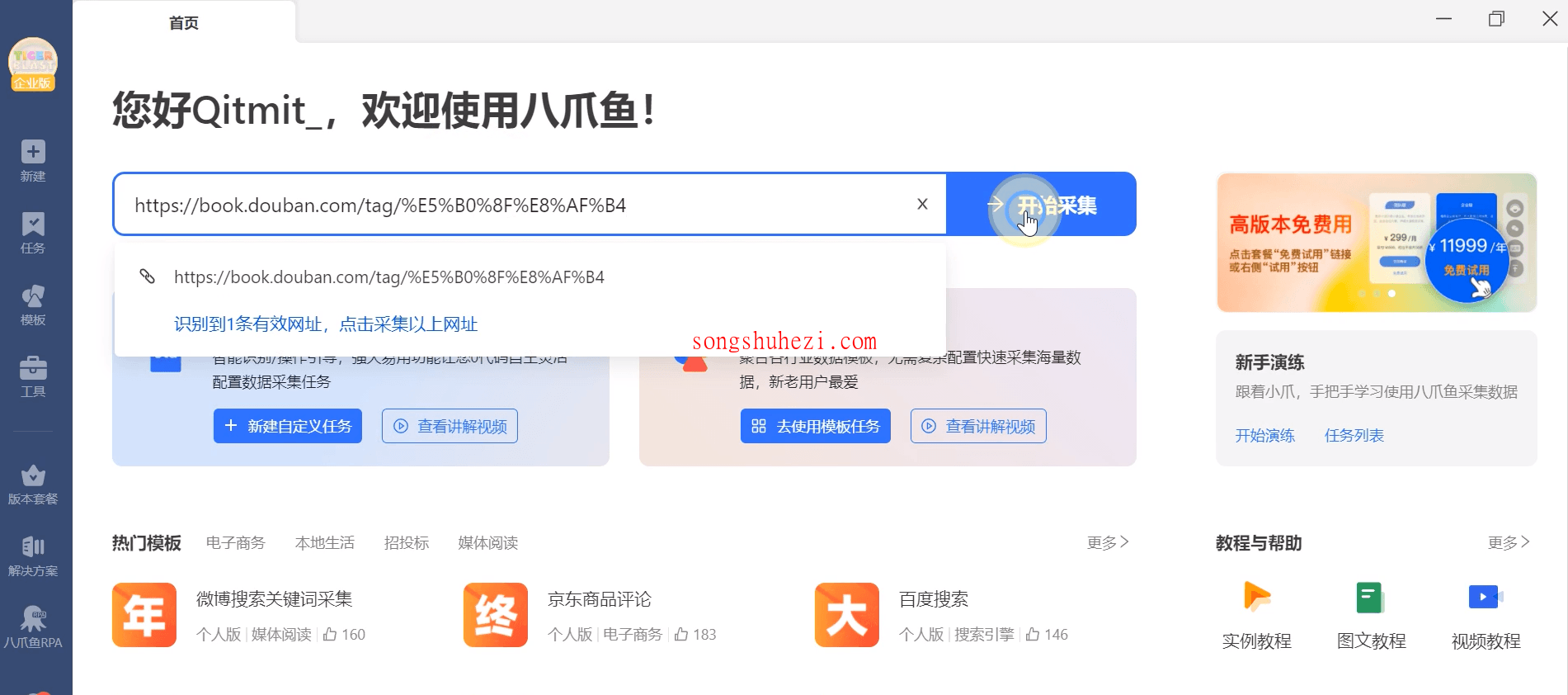
步骤一:输入网址
在八爪鱼的首页输入框中输入你要采集的网页地址(比如豆瓣图书列表的网址),点击【开始采集】按钮,八爪鱼会自动打开该网页。此时,如果八爪鱼开启了智能识别,它会自动进行数据采集的初步配置。如果你不想让它自动识别,可以点击【不再自动识别】或【取消识别】。
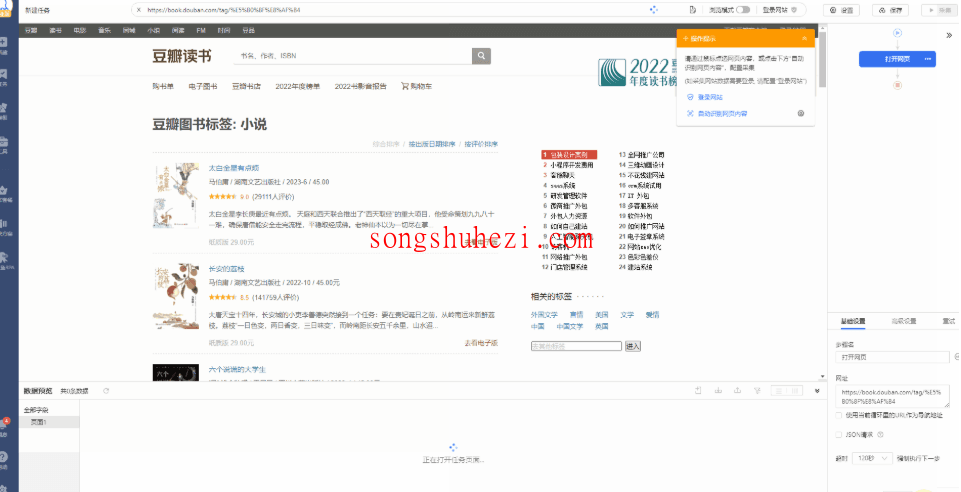
步骤二:建立【循环-提取数据】
在八爪鱼打开网页后,你会看到页面上有很多结构相同的图书列表。每个图书列表包含的字段可能有图书标题、出版信息、评分、评价人数等。我们要做的,就是让八爪鱼识别所有的列表,并且按顺序抓取这些数据。
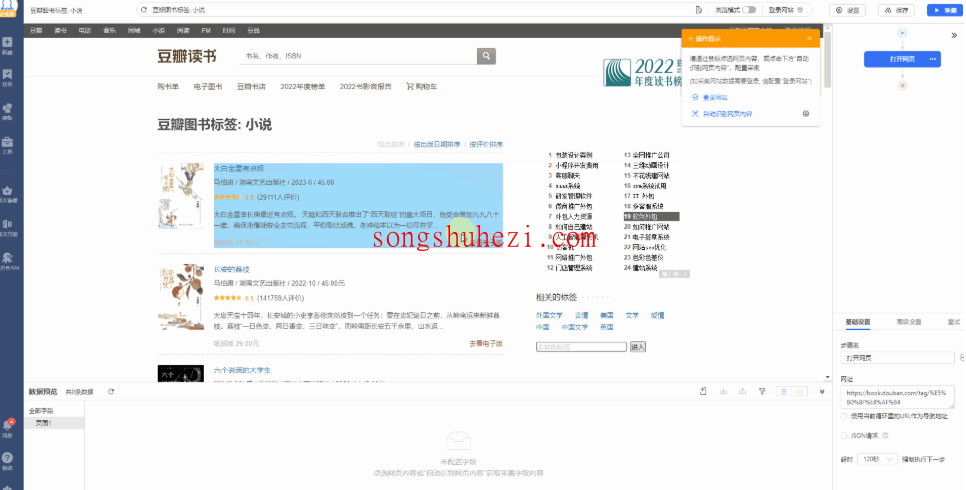
这时,我们就要使用八爪鱼的【循环提取数据】功能。通过这个功能,八爪鱼会自动识别页面上所有相同结构的图书列表,并逐一提取数据。接下来,我们来看具体的操作步骤。
步骤三:选中页面上的图书列表
选中列表:在网页上选择一个图书列表,选中的部分会被绿色框起来,同时出现黄色操作提示框。八爪鱼会识别到该列表的多个【子元素】,这些【子元素】就是图书信息的具体部分,比如图书标题、评分等。

特别说明:
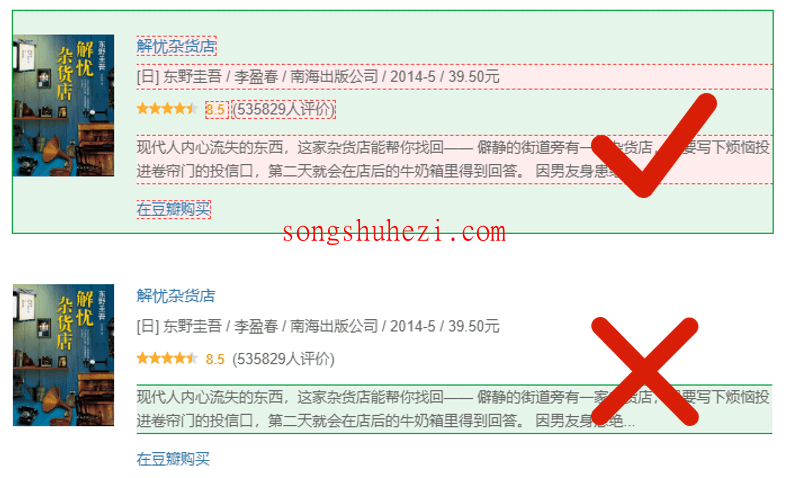
a.选中1个列表,第1个,第2个,第3个...列表都行。
b.在选中列表时,需特别注意范围。被选中的范围(绿色部分)需最大,包括要采集的所有内容。
选中全部子元素:在黄色操作提示框中,选择【选中全部子元素】。此时,八爪鱼会自动选择页面上所有相同的子元素,帮助我们抓取所有图书信息。
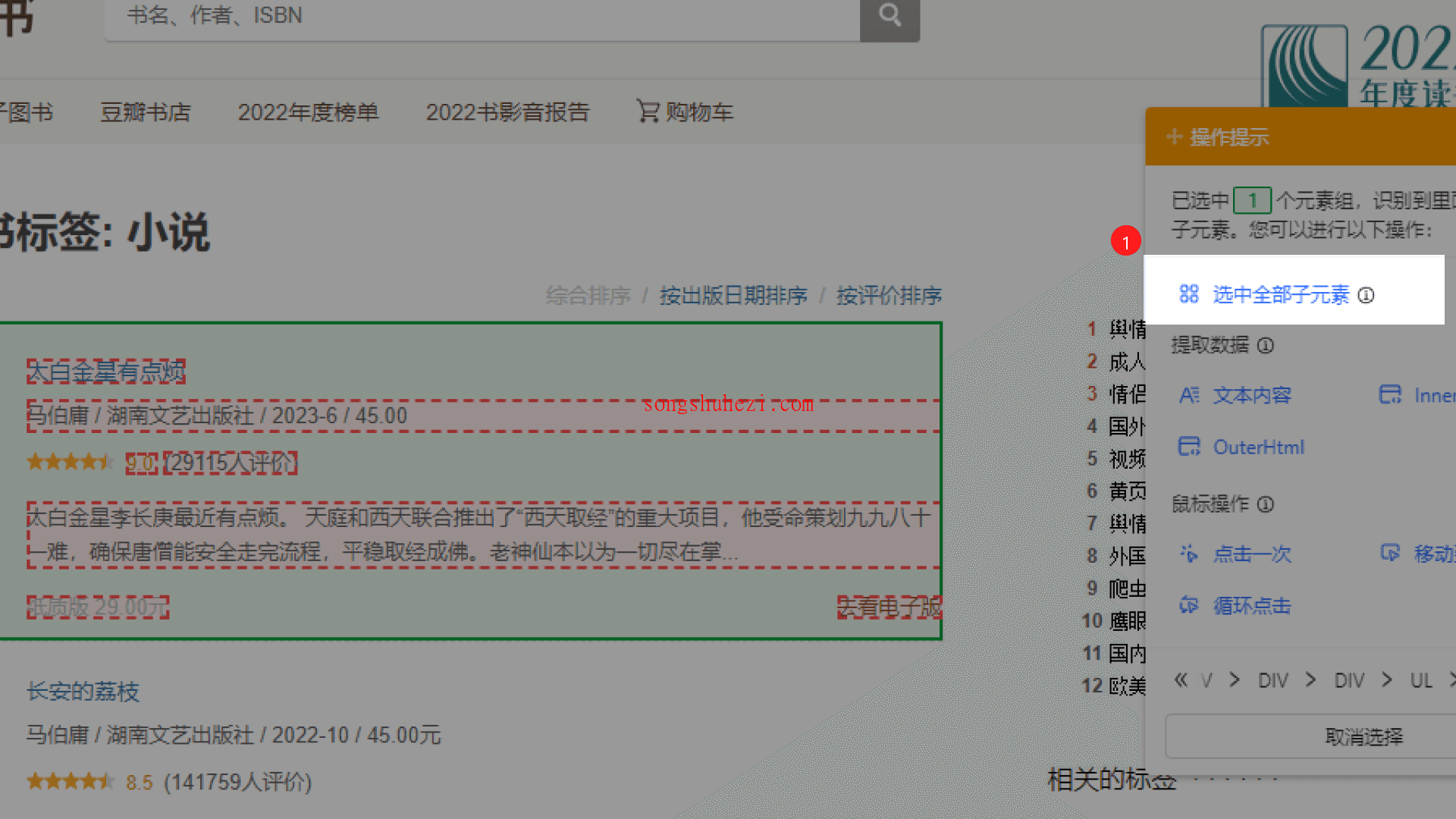
选中所有相似组:接下来,继续点击【选中全部相似组】按钮,这样,八爪鱼就能识别页面中所有相同结构的图书列表了。
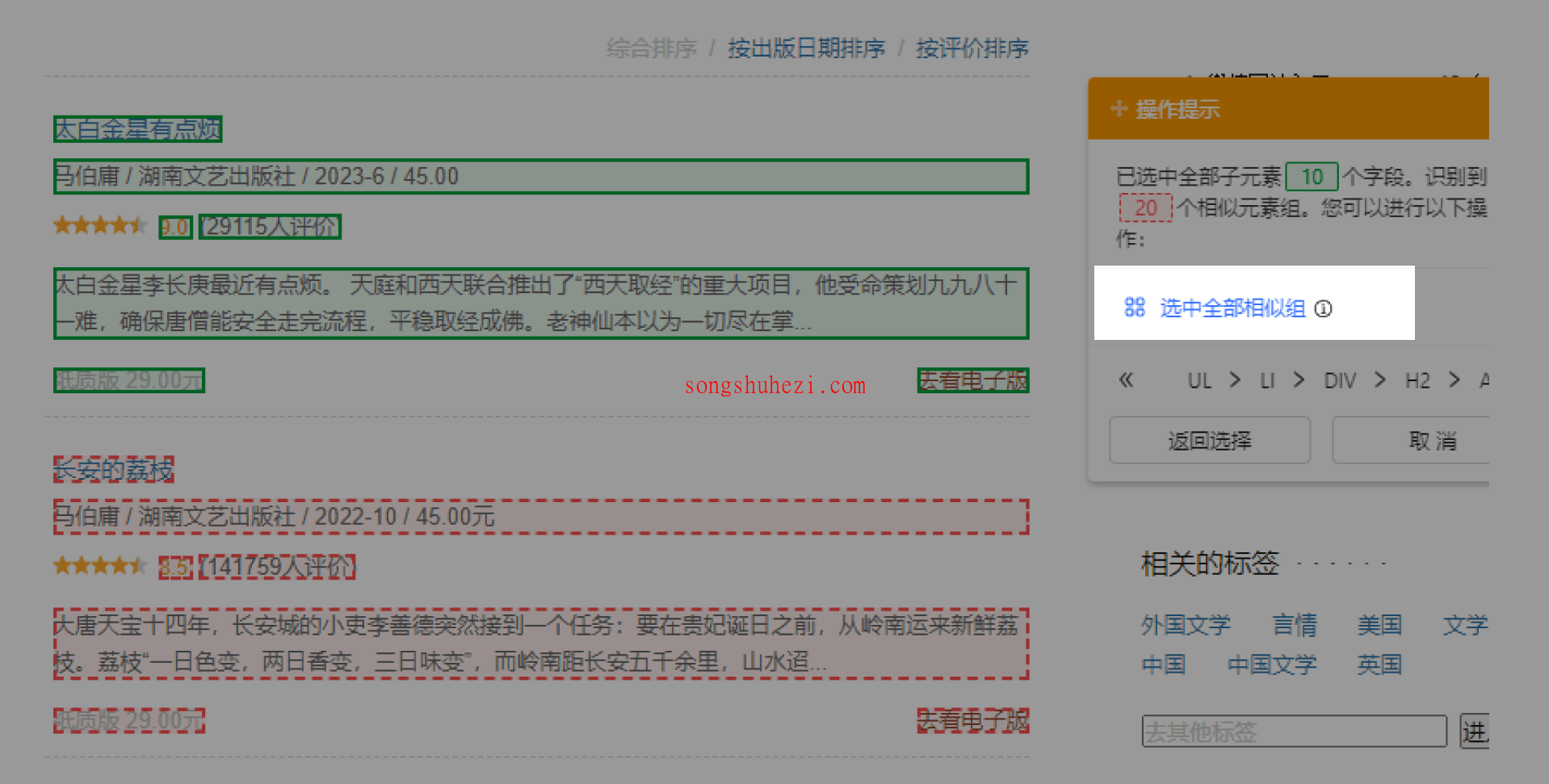
提取数据:最后,选择需要提取的具体数据内容,例如图书标题、出版信息、评分等。此时,八爪鱼会将这些字段自动提取出来,准备进行下一步操作。
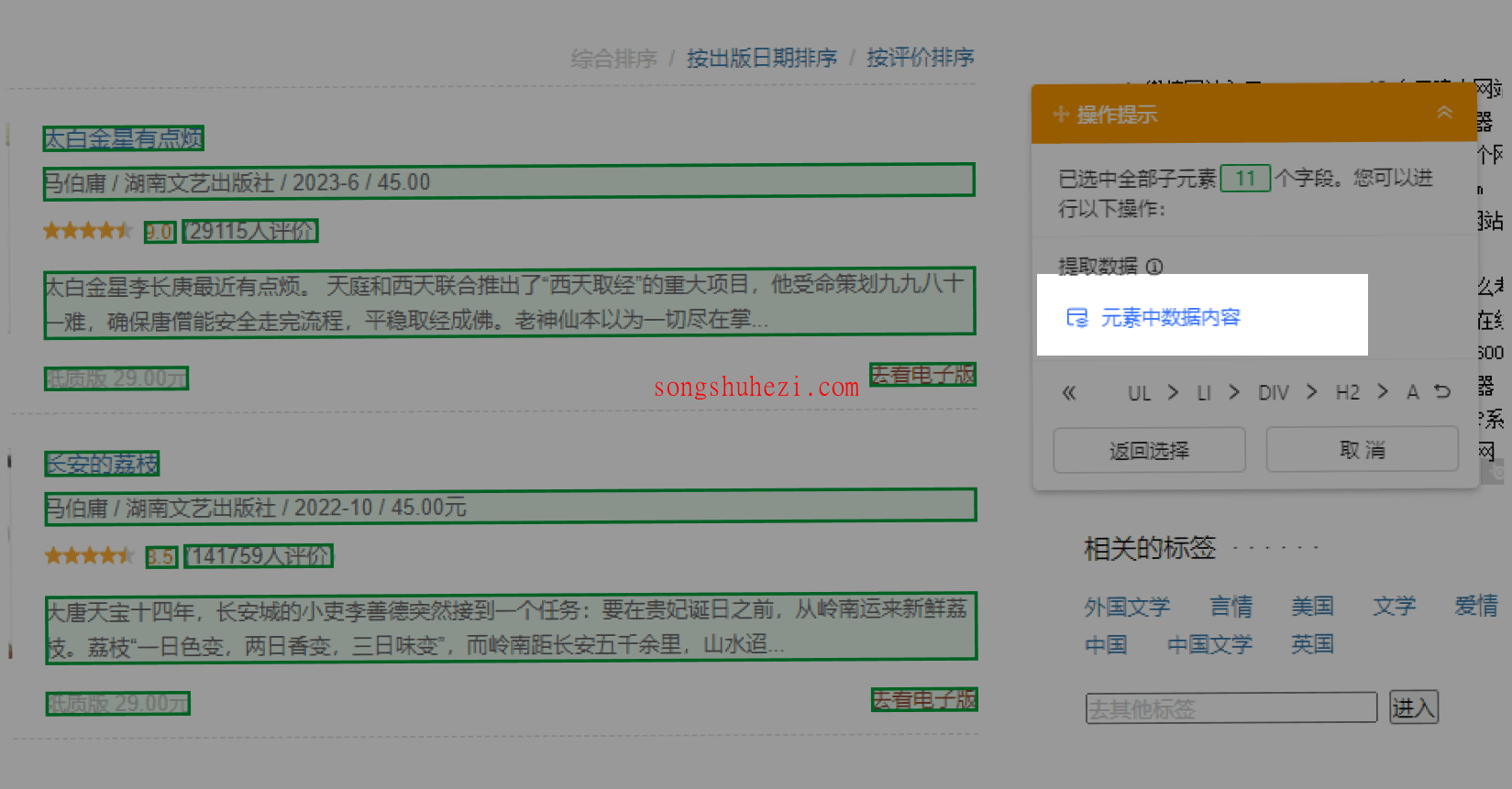
步骤四:编辑字段
当八爪鱼自动提取了所有列表数据后,你可以进入【数据预览】界面,编辑字段名称,修改成你想要的表头。八爪鱼支持两种布局方式:纵向布局和横向布局,你可以根据需要选择合适的布局方式进行编辑。
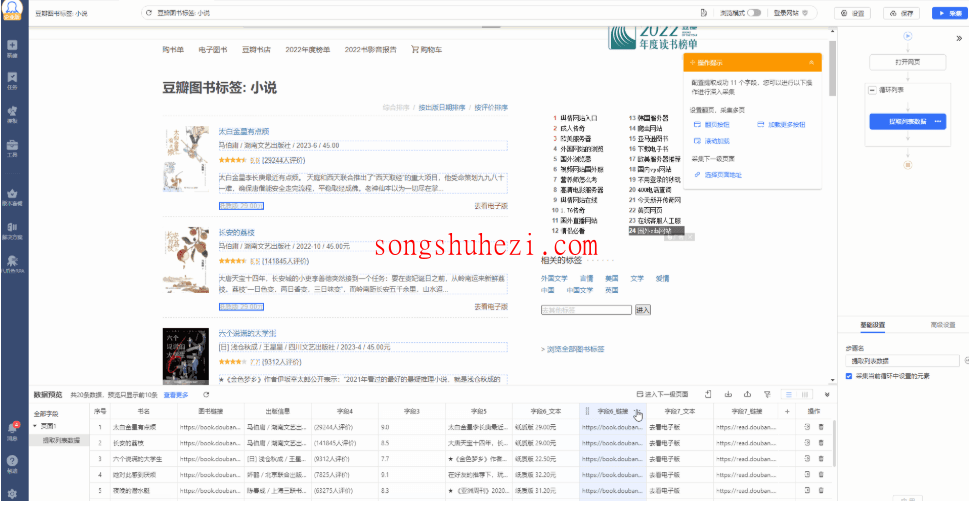
步骤五:启动采集
- 保存设置:完成数据字段的编辑后,点击【保存】按钮,保存当前的采集配置。
- 开始采集:点击【采集】按钮,八爪鱼会开始采集网页上的所有图书信息。如果你选择的是本地采集,那么采集工作会在你的电脑上完成;如果选择云端采集,八爪鱼会使用其云服务器进行采集,速度更快。
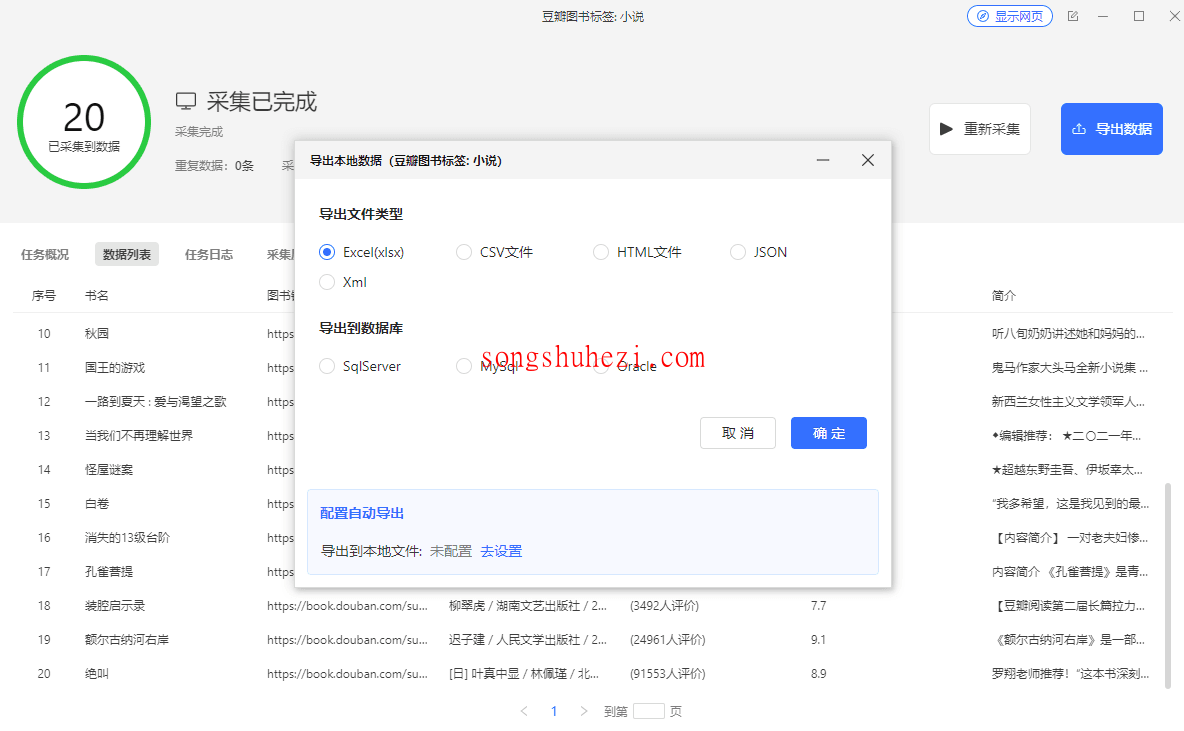
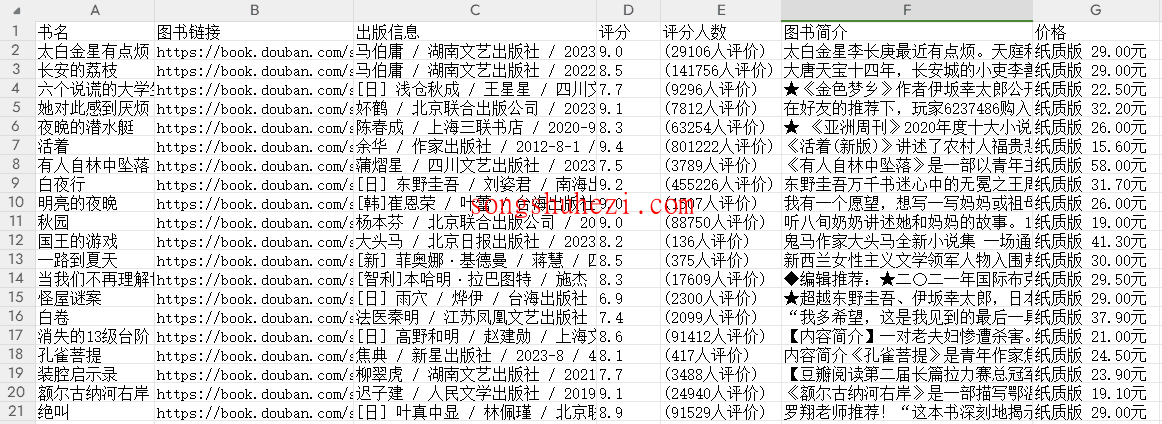
- 导出数据:采集完成后,你可以选择合适的格式导出数据,支持导出为Excel、CSV、HTML等格式。比如,选择导出为Excel,所有采集到的图书信息会按表格形式保存下来,方便后续分析和使用。
三、没有出现【选中全部子元素】的解决方法
在进行【循环提取数据】的过程中,可能会遇到一种情况:选中一个图书列表后,八爪鱼没有显示【选中全部子元素】的选项。这时,可以通过以下方法解决:
- 手动选择列表:继续选中页面上的另一个图书列表,帮助八爪鱼识别页面中所有相同的列表。
- 提取文本内容:在黄色操作提示框中选择【提取数据】→【文本内容】。如果数据被提取到一个单元格中,可以手动选择需要的字段,进行单独提取。
- 添加执行前等待时间:有时候网页加载较慢,可能导致采集不到数据。可以在【循环列表】和【提取数据】步骤之间,添加一定的等待时间,比如设置为4秒,确保网页内容完全加载后再进行采集。
通过这些操作,八爪鱼就能成功识别并提取页面中的所有图书列表数据了。
最后的感受
在使用八爪鱼进行列表数据采集的过程中,我发现它确实是一个非常强大的工具。它能够通过简单的配置,自动抓取网页中的数据,省去了很多手动操作的麻烦。而且,它支持自定义采集流程,帮助我们精准获取所需信息。总体来说,八爪鱼是一个非常高效的数据采集工具,适合各种需求的用户。如果你也需要采集类似的网页数据,不妨试试八爪鱼吧!

反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS