






八爪鱼采集,云采集排错教程
你有没有遇到过这种情况啊?本地采集数据明明跑得好好的,一到云采集就啥也采不到,真的让人头秃。别急啦,这篇就是专门讲怎么排查和解决这种"本地有数据云上没数据"问题的小指南。我自己踩过不少坑了,总结出来的经验,保证实用!
八爪鱼采集器官方链接:https://affiliate.bazhuayu.com/7hypDr
本地有数据,云采集没数据,通常是这几个原因
大概总结一下,问题常出在这四个地方:
- 防采集机制
- 网站本身或者网速问题
- 网络环境不一样导致源码变化
- 网站只允许单浏览器或单IP登录
下面我一个一个跟你说清楚咋处理。
防采集机制搞事情了
云采集最容易踩雷的地方就是防采集了,常见的有三种情况:
- IP被封了
- 出现验证码
- 云端采集需要登录
要搞清楚是不是防采集惹的祸,最靠谱的方法就是:采网页源码来检查。
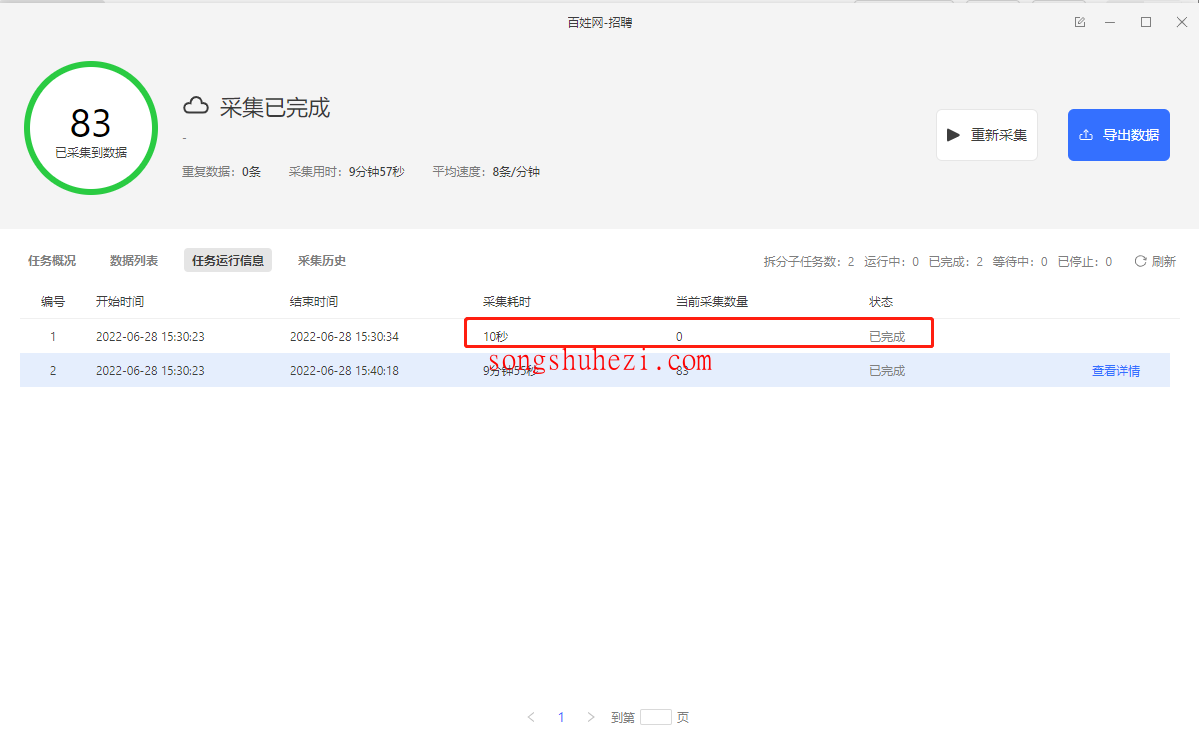
比如我之前用八爪鱼去采百姓网招聘,云端采集一跑就提示采集到的数据是0条。这个时候别慌,我们按步骤来:
- 在采集规则里,加一个【提取数据】的步骤,字段选网页源码。
- 启动云采集,把采到的网页源码复制下来,存成txt,再改后缀成.html。
- 在浏览器里打开这个html文件,看网页长啥样。
如果打开以后发现,网页里跳出来个滑块验证,那基本就是这个验证码挡路了。滑块验证码嘛,八爪鱼暂时搞不定。如果是那种字母+数字的小验证码,还可以设置打码。
要是源码里看到的是网站提示登录或者IP被禁访问,那就更简单了,登录问题就设置云端登录,IP问题的话就开换IP的功能。
总之,一句话:不靠猜,靠源码!
网站或者网速太坑了
有时候你觉得网页打开了,但其实列表数据还在加载中。这种情况在云端超常见。
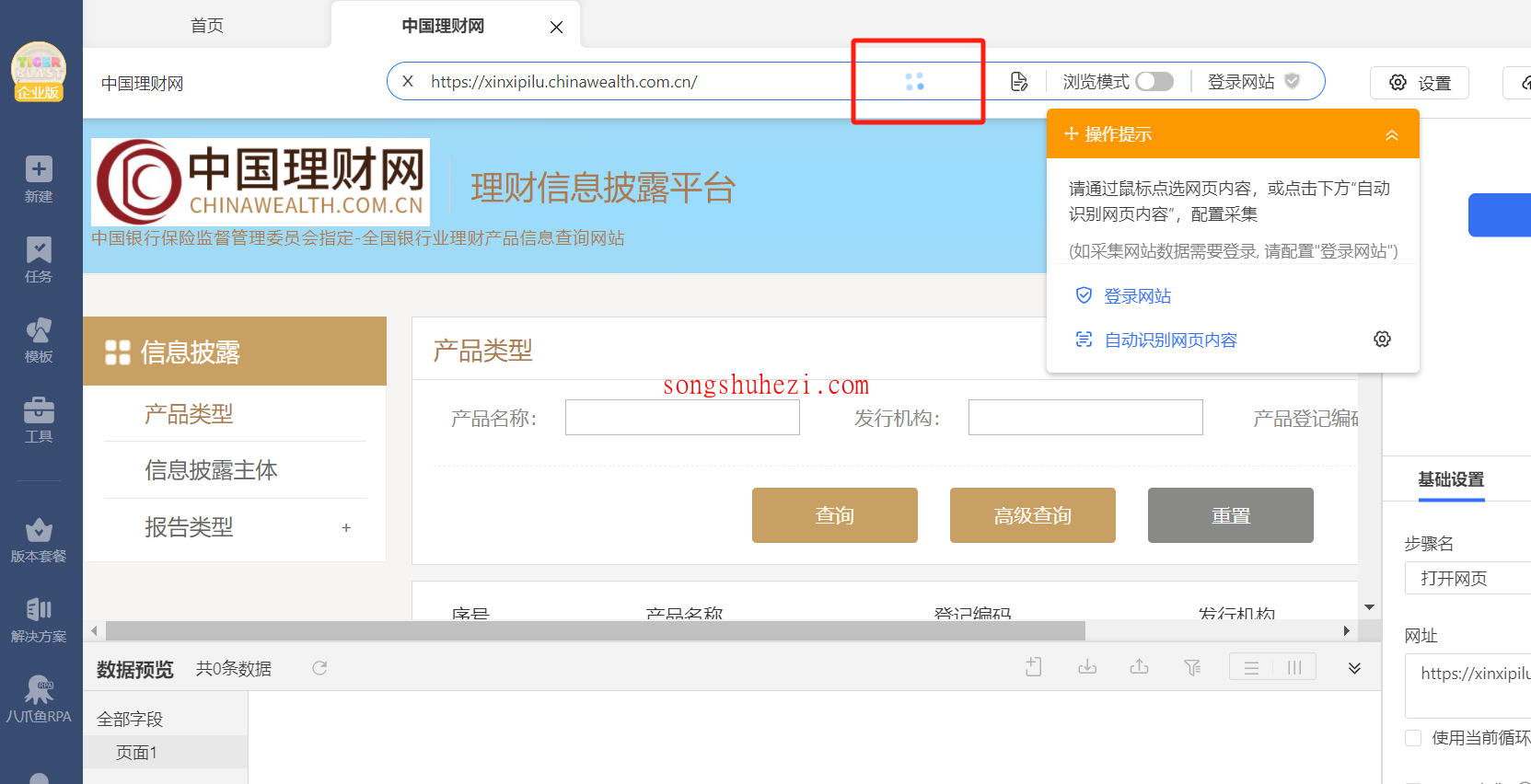
比如网页地址栏已经没有那个小转圈圈了,看起来好像"打开完成"了,但是数据区域是空的。结果八爪鱼一看页面开好了,就急吼吼地执行下一步,结果数据还没出来,当然就采不到啦。
怎么优化呢?很简单:
- 规则里可以加点延时,比如页面打开后等个3-5秒。
- 也可以用八爪鱼的"等待元素出现"功能,让它等列表数据出来再继续。
遇到网速慢或者网站自己慢的,千万不要硬上,耐心点等一等,成功率会高很多。
网络环境不同,导致xpath定位不准
这个坑也是超级隐蔽,特别容易忽略。
有些网站啊,在不同IP、不同地理位置访问的时候,返回的网页源码其实不一样。这种时候,你本地测试的采集规则,到了云端环境就定位失败了。
还是那一招:采源码对比!
- 云端采网页源码,存html文件。
- 用火狐浏览器打开它。
- 检查你的xpath定位有没有对上,如果不准了,就重新写xpath。
这里要稍微懂点xpath语法,建议提前恶补一下,不然调规则真的会怀疑人生。
网站只允许单浏览器或单IP登录
有些网站为了防止账号共享或者刷数据,设置了同一时间只能有一个登录。云采集如果开了任务拆分,多开子任务一起跑,就会直接被踢下来,导致数据为0。

这种情况,云采集一定要设置不拆分任务,就用一个子任务慢慢爬,稳定才是王道!
最后嘛,讲完这些,我自己的感觉是,云采集遇到问题,最重要的就是:别猜!一定要用实际的源码去验证。搞清楚是哪一环出了问题,再对症下药。多试几次,思路清晰了,排错真的没那么可怕了。
你最近有没有遇到什么奇葩的云采集问题呀?要不要跟我说说,看我能不能帮你一起想办法?

反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS