






八爪鱼采集数据去重
在进行数据采集时,我们经常会遇到采集结果中有重复数据的情况。这类问题常常困扰着很多从事数据采集的朋友,特别是在频繁进行数据更新和爬取的过程中,重复数据的出现不仅浪费存储空间,还影响后续数据的分析和处理。在这里,我们介绍八爪鱼采集器提供的两种数据去重方式,帮助大家解决这个问题。
八爪鱼采集器官方链接:https://affiliate.bazhuayu.com/7hypDr
一、按整条数据去重(默认方式)
八爪鱼采集器默认提供了一种去重方式,按整条数据去重。也就是说,系统会将每一行数据的全部字段内容与其他行的数据进行比对,只要两行数据的字段内容完全相同,就认为它们是重复数据。在数据采集完成后,系统会自动去除重复数据,并且只保留重复数据中的第1条。

例子:
假设第1条和第4条数据的全部字段内容完全相同,那么系统会认为它们是重复的,去重后,系统会保留第1条数据,删除第4条数据。
这种去重方式适合那些字段内容完全一致的数据,可以帮助我们避免完全相同的数据重复采集。
二、按字段去重(需手动设置)
除了默认的整条数据去重,八爪鱼采集器还提供了按字段去重的功能,这需要用户手动设置。在制作采集规则时,我们可以选择一个或多个字段作为去重条件,系统会仅根据这些字段的内容来判断数据是否重复。这样,其他未选中的字段即使存在不同,也不会影响数据的去重结果。
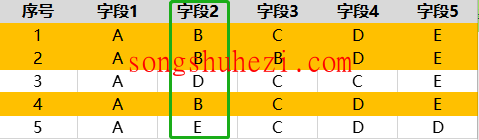
例子1:
假设我们选择【字段2】作为去重字段,系统会比对每一行数据中【字段2】的内容。如果第1、2、4条数据的【字段2】内容相同,系统会认为这三条数据是重复的,去重后仅保留第1条数据。
例子2:
如果我们选择【字段2】和【字段3】作为去重字段,系统会比对这两个字段的内容。如果第1条和第4条数据的【字段2】和【字段3】内容完全相同,那么这两条数据会被认为是重复的,去重后仅保留第1条数据。
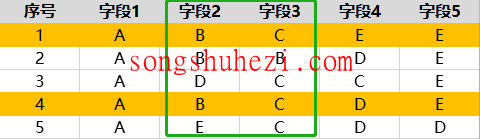
这种按字段去重的方式在处理某些动态变化字段(如评论数、点赞数等)时非常有用,因为这些字段的内容可能随着时间变化,使用此功能可以有效避免无关字段的影响。
三、按字段去重实例
假设我们有一个采集需求:每小时采集某个博主的最新博文,并且需要避免每次都采集到已经采过的内容。我们所采集的字段包括博文内容、评论数、分享数等,但是这些字段中只有博文内容是固定不变的,而评论数、分享数会随着时间不断更新。
此时,八爪鱼采集器的默认去重方式(按整条数据去重)可能无法满足需求,因为每次采集时评论数和分享数的变化会导致整个数据被判定为不同,从而无法去除已采集过的博文。

为了解决这个问题,我们可以使用按字段去重的功能。具体步骤如下:
- 在采集规则中设置好需要采集的字段,包括博文内容、评论数、分享数等。
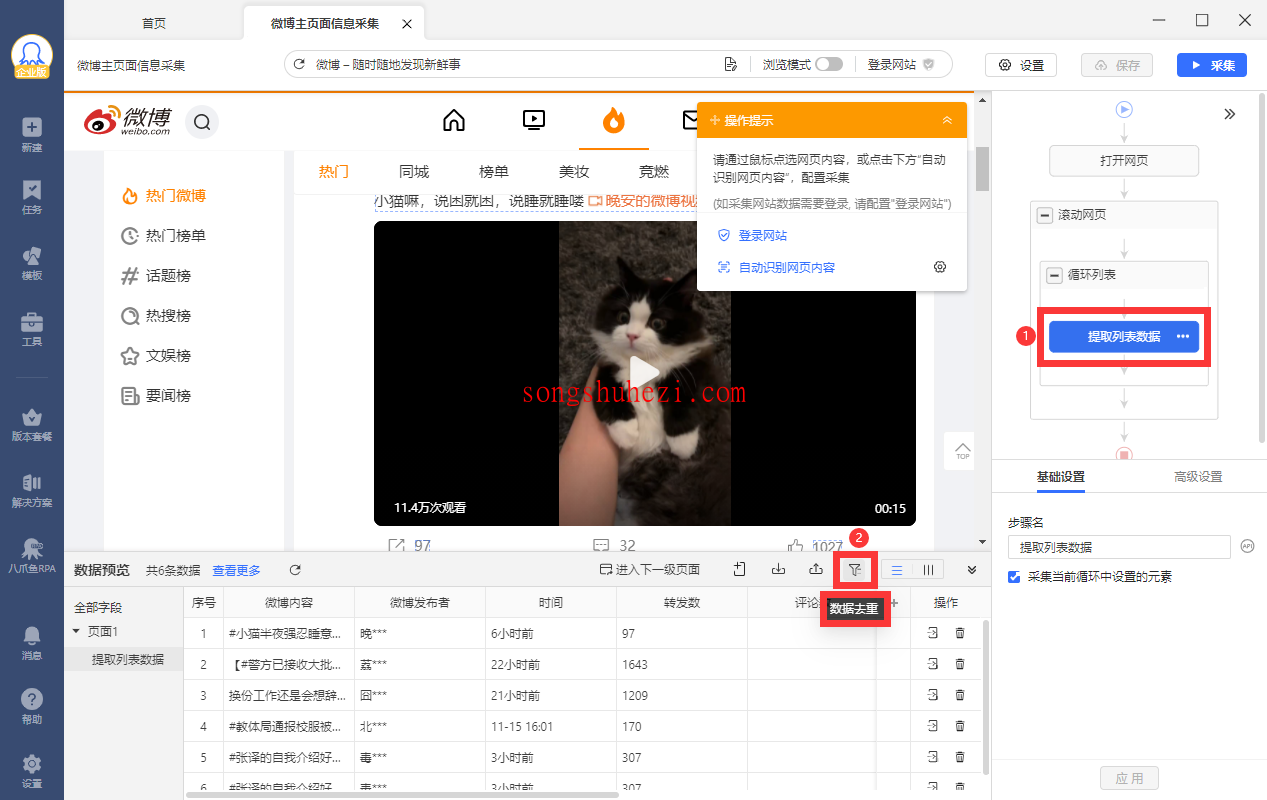
- 在任务流程图中点击【提取数据】步骤,然后点击【数据去重】按钮,进入配置页面。
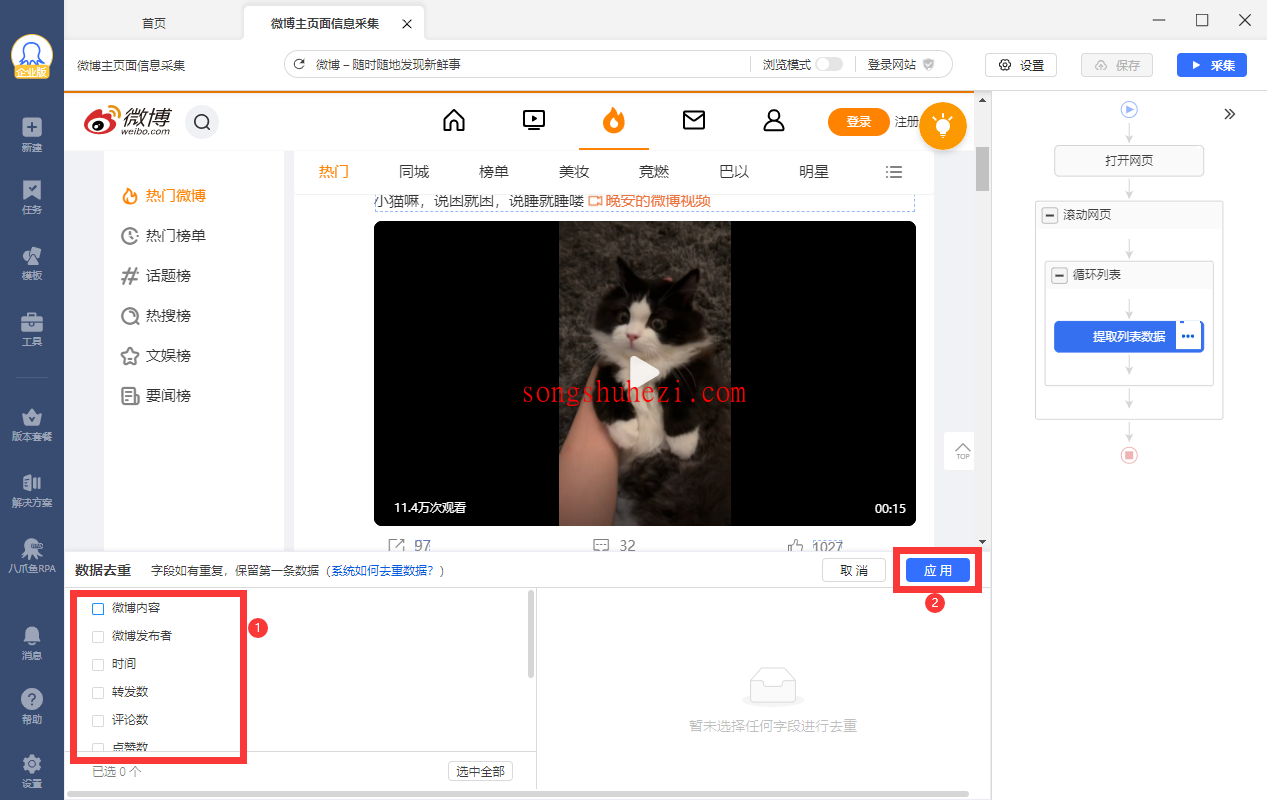
- 选择【博文内容】作为去重字段,这样每次采集时,系统会比对每一条数据的博文内容,只要博文内容相同,就会被判定为重复数据。
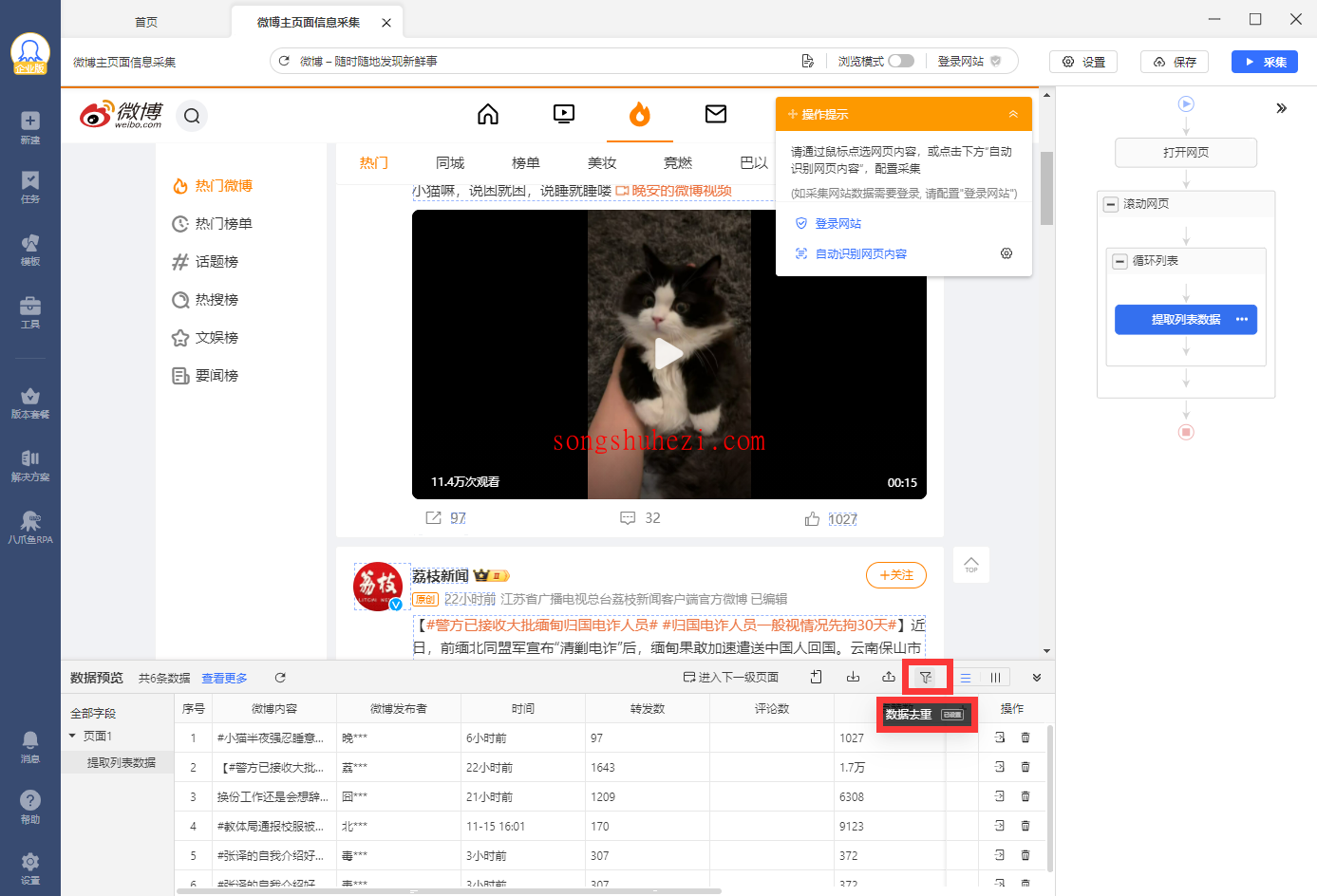
- 点击【应用】后,系统就会按照博文内容进行去重,确保不会重复采集相同内容的博文。
特别说明:
当使用云采集时,数据去重会依据设置的去重条件,对新采集的数据与历史数据进行比较,确保不重复采集已存在的数据。例如:
- 如果第一次设置去重条件为【字段1】,那么系统会对比并去重第一次采集的数据。
- 修改去重条件为【字段2】后,第二次采集的数据不会和第一次的数据进行对比去重。
- 如果再次将去重条件改回【字段1】,系统会对比第三批数据与第一次数据的内容,进行去重。
这种方式特别适用于需要定时、周期性采集的任务,能够避免每次采集时重复抓取相同的数据。
总结
八爪鱼采集器提供的两种去重方式—按整条数据去重和按字段去重—为用户提供了灵活的数据去重选项。无论是简单的整条数据去重,还是精细的按字段去重,都能帮助用户高效地去除重复数据,提高数据的准确性和质量。掌握这些去重技巧,可以让你在进行数据采集时更为高效和精准。

反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS