






八爪鱼采集按钮翻页
你有没有遇到过这样的网站,页面上没有明确的“下一页”按钮,只有“加载更多”或者“再显示20条”这种按钮,点击一次后页面会继续加载新的数据,直到没有更多内容为止?像果壳网、百度贴吧这些网站就是这样。想要在这类页面上采集数据,传统的翻页方法就不适用了,得依赖不断点击“加载更多”按钮来实现翻页。
那么,如何通过八爪鱼来实现这一点呢?其实,八爪鱼不仅支持智能识别这种翻页方式,还能手动配置采集规则,帮助你精准地获取这些“加载更多”按钮后的数据。接下来,就让我们一起来了解如何在八爪鱼中配置这些设置吧。
八爪鱼采集器官方链接:https://affiliate.bazhuayu.com/7hypDr
一、使用智能识别实现【点击加载更多翻页】
八爪鱼的智能识别功能已经支持对“加载更多”按钮的翻页操作。下面是如何在果壳网这种类型的页面上使用智能识别进行翻页设置:
Step 1:输入网址并启动采集
首先,在八爪鱼的首页输入目标网址(例如果壳网),点击【开始采集】按钮,八爪鱼会自动打开该网页。
Step 2:启用智能识别
打开网页后,选择【智能识别网页】选项,等待八爪鱼自动识别网页内容。识别完成后,八爪鱼会自动识别到页面上的“加载更多内容”按钮,并根据需要生成采集规则。
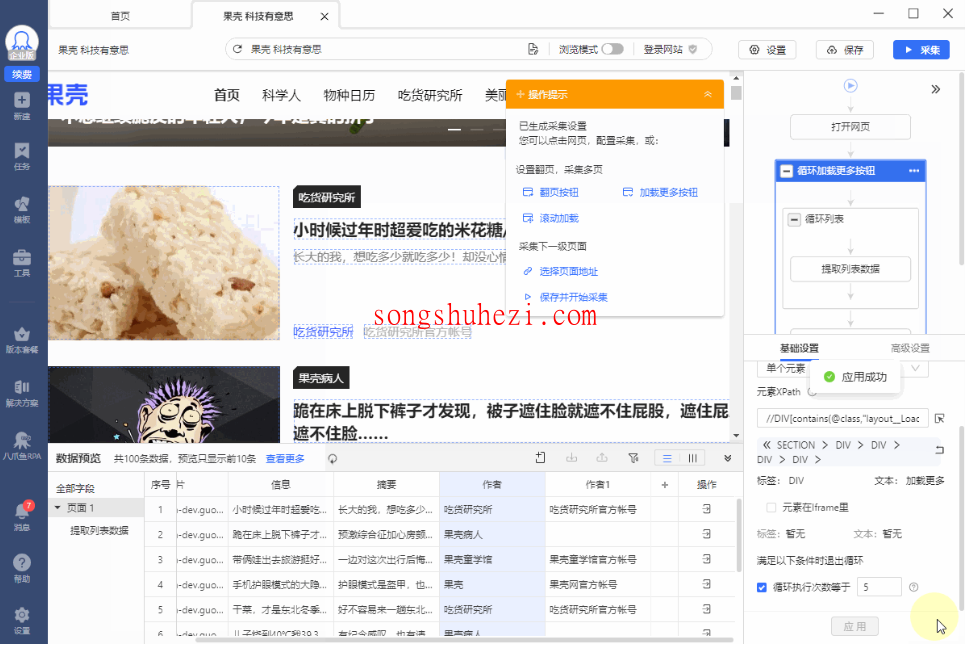
Step 3:设置翻页次数
由于部分网站的“加载更多内容”按钮是无限制的,如果没有设置点击次数,八爪鱼可能会一直点击下去,导致程序崩溃或者无法成功采集数据。因此,建议你设置一个合理的点击次数。
例如,在果壳网的页面上,可能点击5次“加载更多内容”按钮后就到达页面底部,页面不再加载新的内容。此时,我们可以将翻页次数设置为5次。
Step 4:开始采集
点击【开始采集】,八爪鱼会自动按设置的次数点击“加载更多内容”按钮,并在翻页完成后采集所有加载出来的列表数据。
二、手动配置采集流程实现【点击加载更多翻页】
如果你不想使用智能识别,也可以通过手动配置采集流程来实现点击“加载更多”按钮的翻页操作。以下是详细步骤:
Step 1:输入网址并启动采集
同样,在首页输入目标网址,点击【开始采集】进入采集页面。
Step 2:配置循环列表
选择你需要采集的数据元素(如文章标题、链接等),并创建一个【循环列表】。这样,八爪鱼会根据页面内的规则循环采集数据。

Step 3:配置翻页规则
接着,在页面中找到“加载更多”按钮,并在右侧的采集规则栏中,依次点击【加载更多按钮】。这样,八爪鱼会在每次点击后采集新的数据。
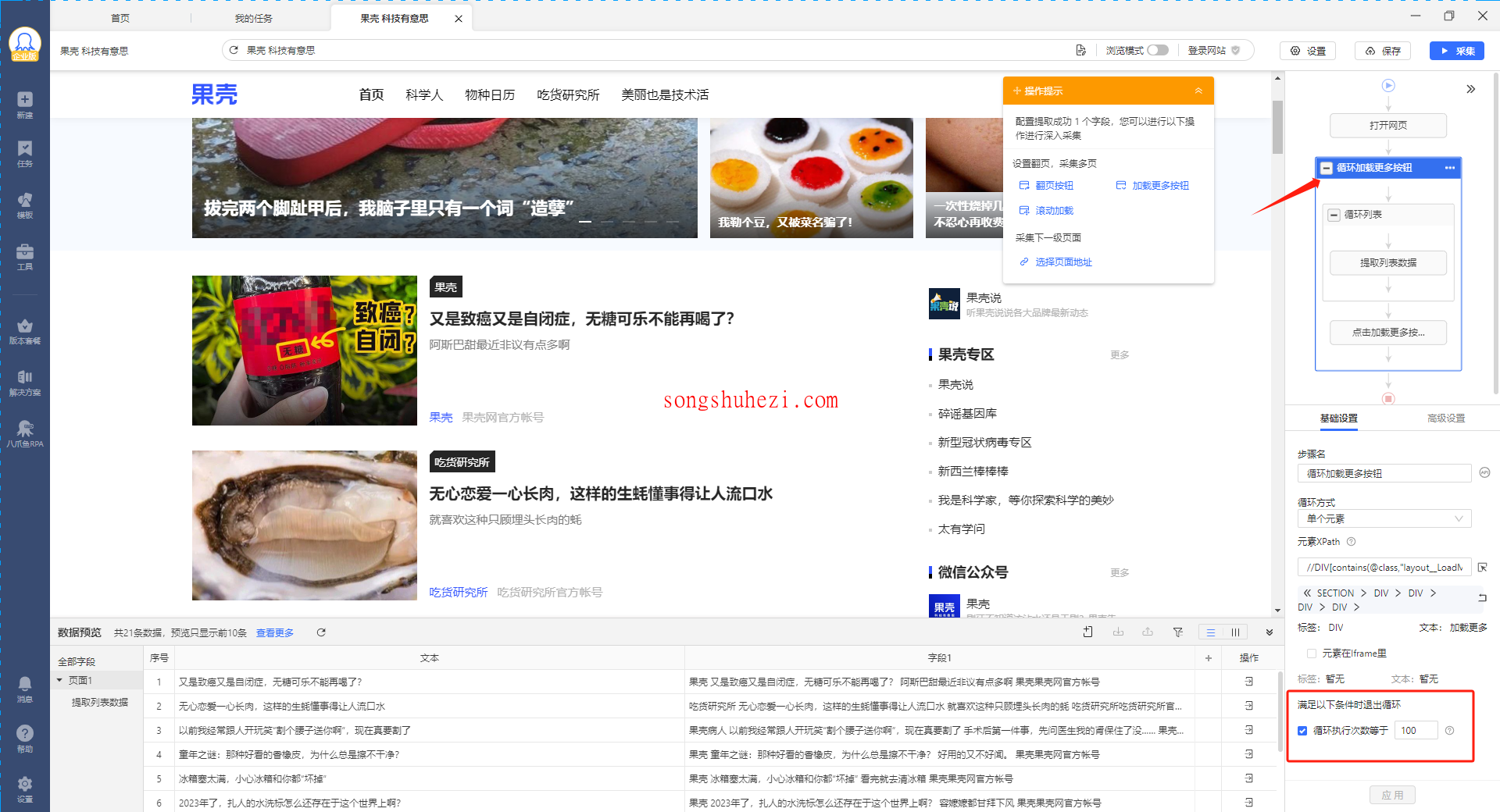
Step 4:设置翻页次数
根据网页的情况,你可以在循环列表中设置点击“加载更多”按钮的次数。例如,设置点击5次。每点击一次,八爪鱼会获取新的数据。
Step 5:开始采集
设置完成后,点击【开始采集】,八爪鱼将根据你设置的翻页次数,自动执行点击“加载更多”按钮的操作并采集相应的数据。
三、特别说明
在采集过程中,八爪鱼支持数据去重功能。这样,如果你不介意采集到重复的数据,可以直接使用默认的采集规则,系统会自动过滤掉重复的数据。
但如果你希望在采集过程中避免重复数据,建议根据页面情况合理调整采集规则。例如,你可以设定更精确的过滤条件,或者在采集过程中实时检查数据的唯一性。
总结
通过八爪鱼的智能识别和手动配置功能,我们可以轻松实现点击“加载更多”按钮进行翻页并采集新数据的操作。对于那些没有明确翻页按钮的网站,这个功能无疑是非常实用的。无论你选择智能识别还是手动配置,都可以根据需求灵活调整设置,保证数据采集的效率和准确性。
在我个人使用八爪鱼进行采集时,这个“点击加载更多翻页”功能极大地提升了我的工作效率,尤其是在面对一些需要反复点击按钮加载数据的页面时,真的是帮了大忙。如果你也常常遇到这种情况,不妨尝试一下这个功能,相信你一定会有不错的体验。

反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS