






Web Scraper Cloud:如何利用云端服务提升数据抓取效率
Web Scraper Cloud 是Web Scraper的高级服务,提供了自动化、可扩展性和更稳定的抓取性能。与本地浏览器扩展不同,Web Scraper Cloud通过云端执行抓取任务,可以自动处理IP地址旋转、数据存储、进度监控和任务调度。该服务特别适合需要大量抓取任务的用户,帮助他们更高效地完成抓取工作。
Web Scraper Cloud的主要功能
1. Proxy(代理)
代理服务用于防止抓取时被目标网站屏蔽,并可通过代理访问地理限制的网站。Web Scraper Cloud默认使用位于美国的IP地址,并每5分钟轮换一次。如果需要其他区域的IP地址,可以联系支持团队。对于高级用户,还可以集成第三方代理服务。
- 自动IP轮换:每5分钟自动更换IP地址,防止因频繁访问而被封禁。
- 重试机制:如果页面加载失败,抓取器会更换IP并重新尝试抓取。
2. 调度器(Scheduler)
Web Scraper Cloud允许设置定时任务,通过调度器定期运行抓取任务,自动化你的数据采集工作。
3. API
通过API,你可以控制抓取任务的创建、启动、停止和数据提取等操作,实现更灵活的抓取管理和集成。
4. 数据导出
抓取的数据可以自动导出到多种格式,包括CSV、JSON等,方便后续分析或导入到其他系统。
5. 数据质量控制
Web Scraper Cloud内置了数据质量控制功能,自动检测空白页面和抓取失败的页面,并进行重新抓取。这样你可以确保抓取的数据质量稳定,不会遗漏重要信息。
6. 通知功能
你可以设置通知,在抓取任务完成或失败时接收提醒,确保你时刻了解抓取的进展。
7. Sitemap同步
通过Sitemap同步功能,你可以将Web Scraper浏览器扩展创建的Sitemap同步到云端,方便在Web Scraper Cloud上运行抓取任务。
8. 页面积分(Page credits)
页面积分代表了每次加载页面时的计费方式。例如,如果抓取100个页面,则会消耗100个页面积分。如果你从一个页面提取多个记录,只会消耗一个页面积分。空白页面或抓取失败的页面不会扣除积分。
9. 并行任务(Parallel tasks)
并行任务允许你同时运行多个抓取任务。如果并行任务已满,新的任务将排队等待。你可以手动停止或调整任务顺序,以便更灵活地分配资源。
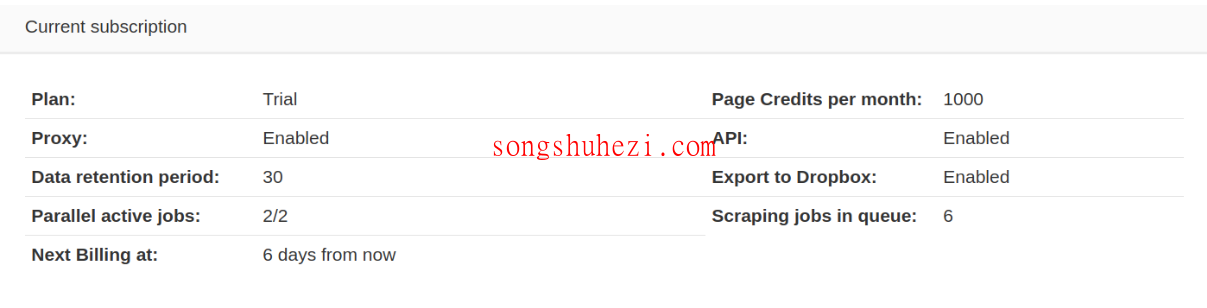
10. 抓取进度监控
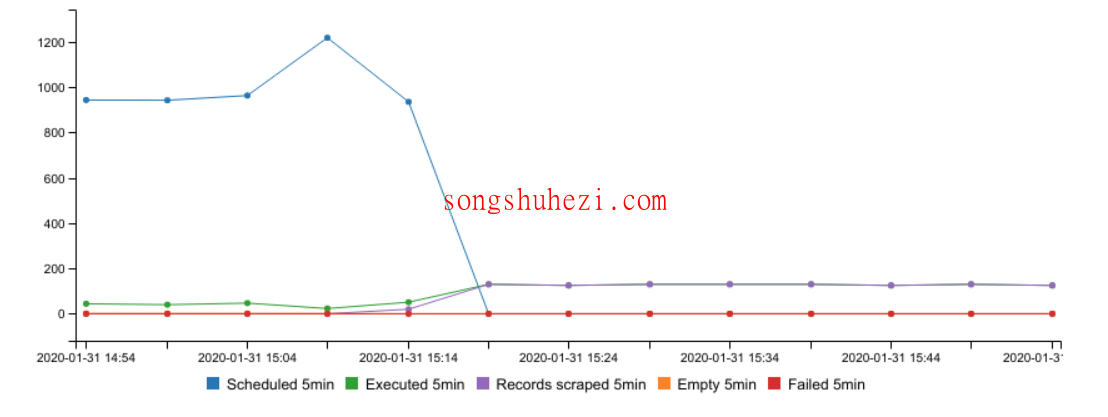
在Web Scraper Cloud中,你可以通过任务列表查看每个抓取任务的进度,包括已抓取的页面、提取的数据记录、失败的页面以及空白页面。抓取任务的性能图展示了5分钟间隔的执行状态,帮助你了解任务的实时进展。
11. 任务检查与故障排除
Web Scraper Cloud允许你在抓取任务的列表中查看失败的页面截图(仅限Full driver模式),并提供性能图表帮助你分析抓取过程中的问题。如果有需要,你可以手动继续抓取任务,确保数据的完整性。
Web Scraper Cloud的优势
1. 自动化与可扩展性
通过调度器和并行任务管理,你可以轻松实现数据抓取的自动化,并根据需求同时运行多个任务。Web Scraper Cloud通过云端处理这些任务,避免了本地资源的限制。
2. 更高的数据抓取成功率
Web Scraper Cloud提供了IP地址轮换、失败页面重试以及数据质量控制,确保你抓取到的内容完整且准确。特别是对于容易被封禁的网站,代理功能大大提升了成功率。
3. 云端存储与灵活导出
所有抓取数据都存储在云端,且可以导出为多种格式。这意味着你可以随时访问历史数据,甚至在不同的任务之间共享和复用这些数据。
4. 高效的抓取性能
Web Scraper Cloud提供两种抓取驱动方式:Full driver和Fast driver。Full driver适合需要执行JavaScript的网站,而Fast driver则通过提取原始HTML数据,减少页面加载时间,提升抓取速度。
5. 灵活的代理设置
如果你需要特定地区的IP地址或自定义代理服务,Web Scraper Cloud允许你集成第三方代理,满足复杂的抓取需求。
Web Scraper Cloud与浏览器扩展的对比
| Web Scraper Cloud | Web Scraper浏览器扩展 |
|---|---|
| 提供自动故障转移、IP轮换,降低封禁风险 | 仅能抓取用户在浏览器中访问的站点 |
| 数据存储在云端,历史任务数据长期可用 | 仅存储最新一次抓取任务的数据 |
| 不加载图片,减少页面加载时间 | 加载图片,增加页面加载时间 |
| URL以伪随机顺序抓取,确保抓取最新数据 | URL按发现顺序抓取,不能优先抓取最新数据 |
最后感受
在我看来,Web Scraper Cloud是一款强大的云端数据抓取解决方案,尤其适合需要抓取大量数据或处理复杂网站的用户。它通过代理服务、自动化调度、并行任务和灵活的API,极大提高了数据抓取的效率与稳定性。如果你经常需要从网页上抓取数据,并希望提升抓取成功率和自动化程度,Web Scraper Cloud无疑是你最好的选择!

反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS