






EasySpider如何截取网页的完整图像
在你使用无头模式(headless mode)运行自动化任务的时候,比如要截取整个网页的截图,可能会遇到截图不完整的问题。
问题背景
在无头模式下运行浏览器时,由于没有实际的图形界面,默认的浏览器窗口尺寸较小,所以截图只能捕获部分页面。如果网页内容较长,截图结果往往不完整,就像用户遇到的情况一样。
用户提供了以下信息:
- 无法通过无头模式截取京东网页的完整图像
- 截图的大小固定在779 x 579
- 即使在有头模式下调整窗口大小,也只能截取可见区域,无法获取整个页面
解决方案
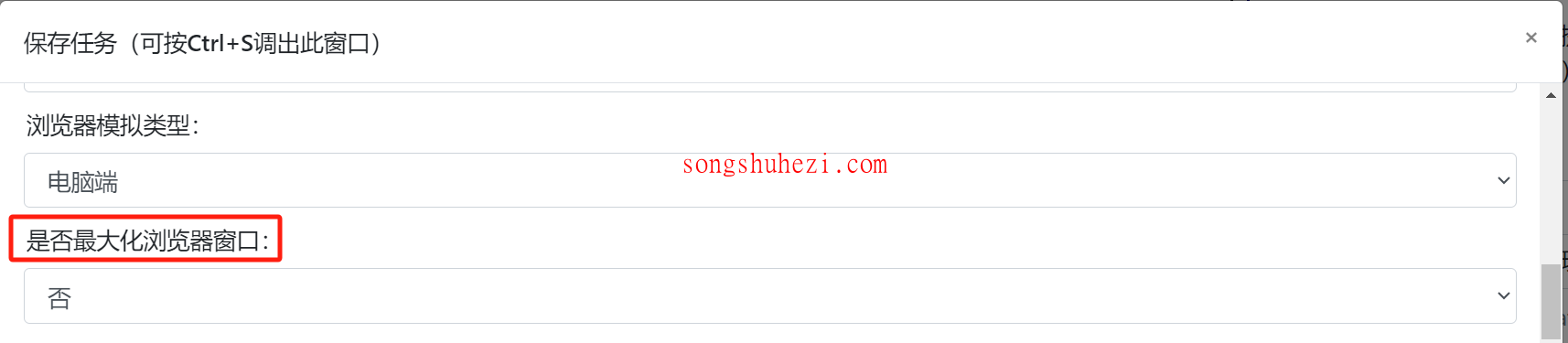
针对这个问题,项目维护者给出了一个简单但有效的解决方法:通过代码设置浏览器的窗口尺寸。在截图操作之前,可以自定义调整浏览器窗口的大小,确保能够截取整个网页。
具体步骤如下:
使用Python代码调整窗口大小
在执行截图操作前,添加一个自定义操作,执行以下Python代码,将窗口大小设置为你需要的尺寸:pythonself.browser.set_window_size(1800, 19600)这个代码中的
1800是窗口的宽度,19600是窗口的高度。根据网页的实际长度,你可以自定义调整这个高度参数。运行无头模式命令
在执行浏览器任务时,使用以下命令行来运行无头模式:bash--headless 1这样,浏览器会在无头模式下启动,同时应用你设置的窗口尺寸,确保截图能够覆盖整个页面。
注意事项
登录问题:在无头模式下,很多用户会遇到无法进行登录的问题。这时,可以尝试在带有用户信息的模式下运行任务,确保可以通过登录验证。也可以在有头模式下登录一次,然后保存cookie,之后再用无头模式进行截图任务。
截图拼接:如果网页内容非常长,单纯调整窗口尺寸可能无法满足需求,可能需要写代码通过多段截图的方式将整个页面的截图拼接起来。这种方式需要一定的代码量,但可以保证网页的每一个部分都被截图覆盖。
在无头模式下截取网页完整图像,最简单的解决方案就是调整浏览器的窗口尺寸,确保窗口足够大,能够容纳整个页面的内容。通过自定义窗口大小,再结合无头模式,你就可以顺利获取到完整的网页截图。
如果网页非常长,你还可以选择通过多段截图和拼接的方式来实现更复杂的截图需求。在我看来,这个方法简单又有效,值得一试!

反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“RPA编程教程”或者“rpa1499” 或微信扫描上方二维码关注微信公众号



 RSS
RSS