






Stable Diffusion 基础与ComfyUI的初步结合
在深入学习 ComfyUI 的使用之前,理解其背后的 AI 绘图工具——Stable Diffusion的基础原理是至关重要的。这不仅可以帮助你更好地掌握工具的操作,而且能让你在使用过程中更有创造性。接下来,我将从 Stable Diffusion 的基本概念开始,逐步引入如何结合 ComfyUI 进行高效的图像创作。
Stable Diffusion 的核心工作原理
Stable Diffusion 是一个复杂的 AI 图像生成系统,它主要包括三个关键组件:Text Encoder、Image Information Creator(图像信息创建器)、Image Decoder(图像解码器)。理解这三部分的工作原理是掌握 Stable Diffusion 的关键。
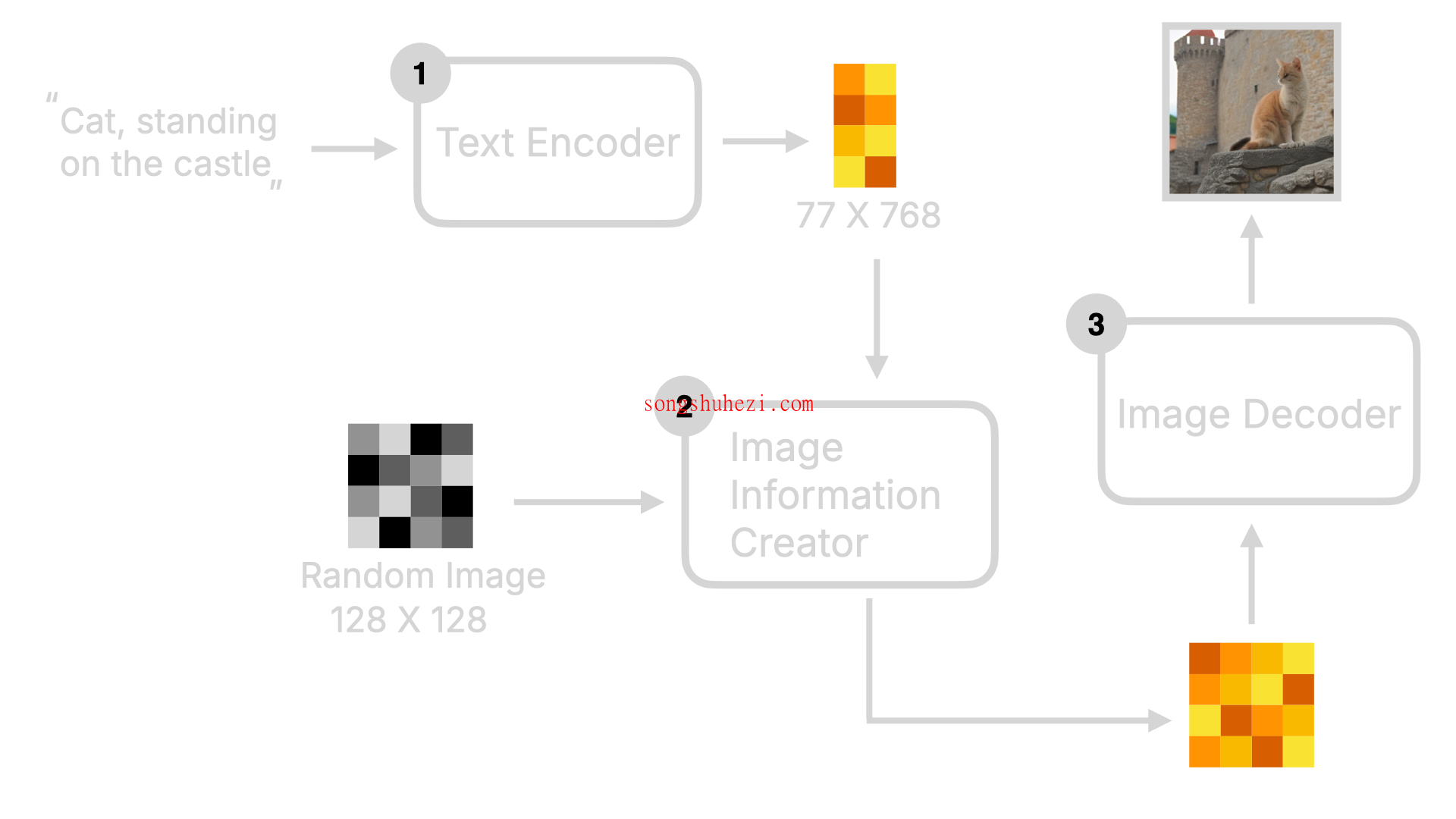
Text Encoder:将输入的文字描述(Prompt)转换为机器可以理解的数值向量。这些向量将作为生成图像的语义基础。
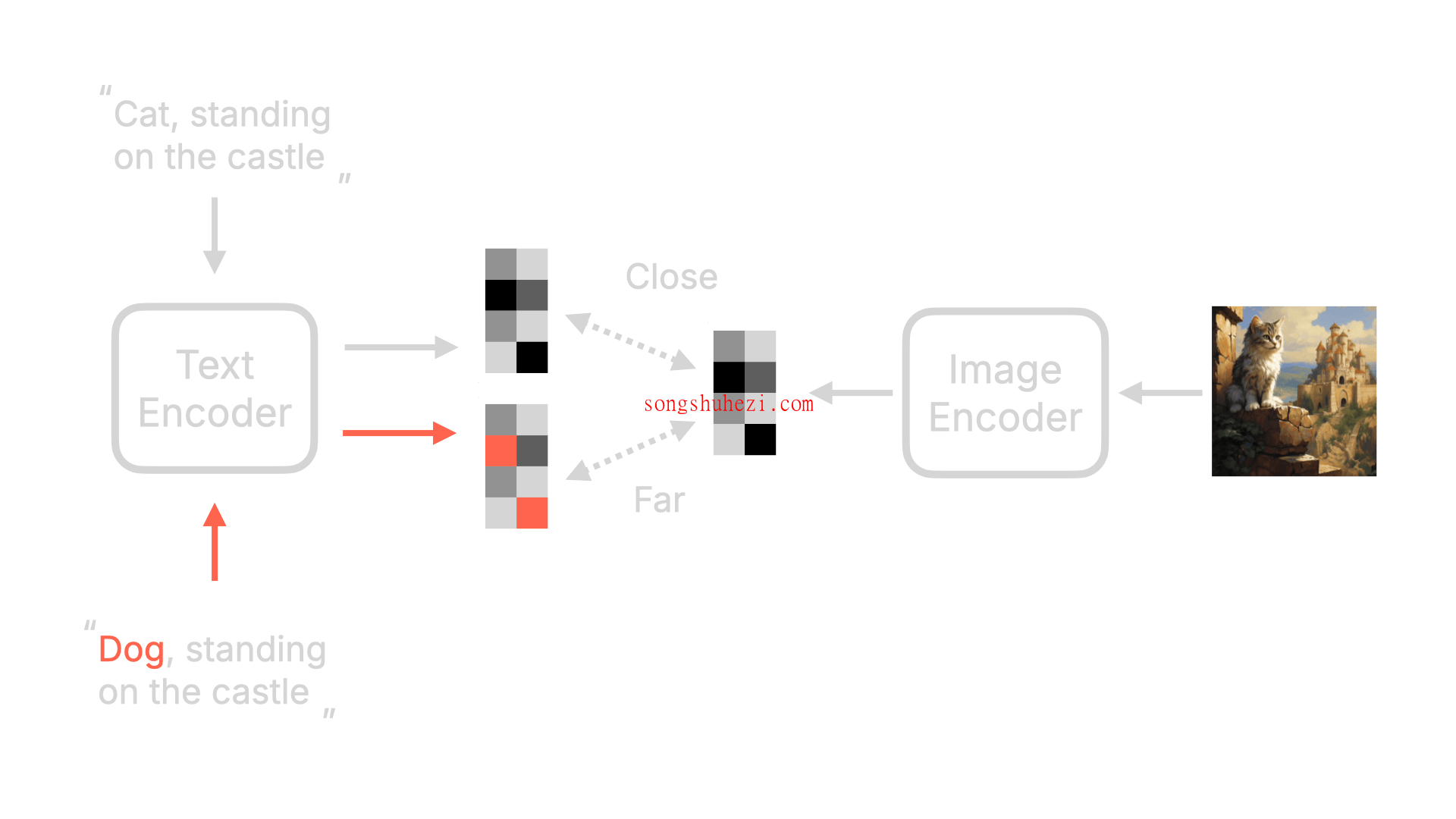
Image Information Creator:这个组件接收来自 Text Encoder 的向量和一张含有随机噪点的初始图像,通过一系列的“降噪”步骤逐渐将其转化为含有详细图像信息的中间数据。这一过程涉及多个步骤的迭代,每一步都在逐渐清晰和精确图像的细节。
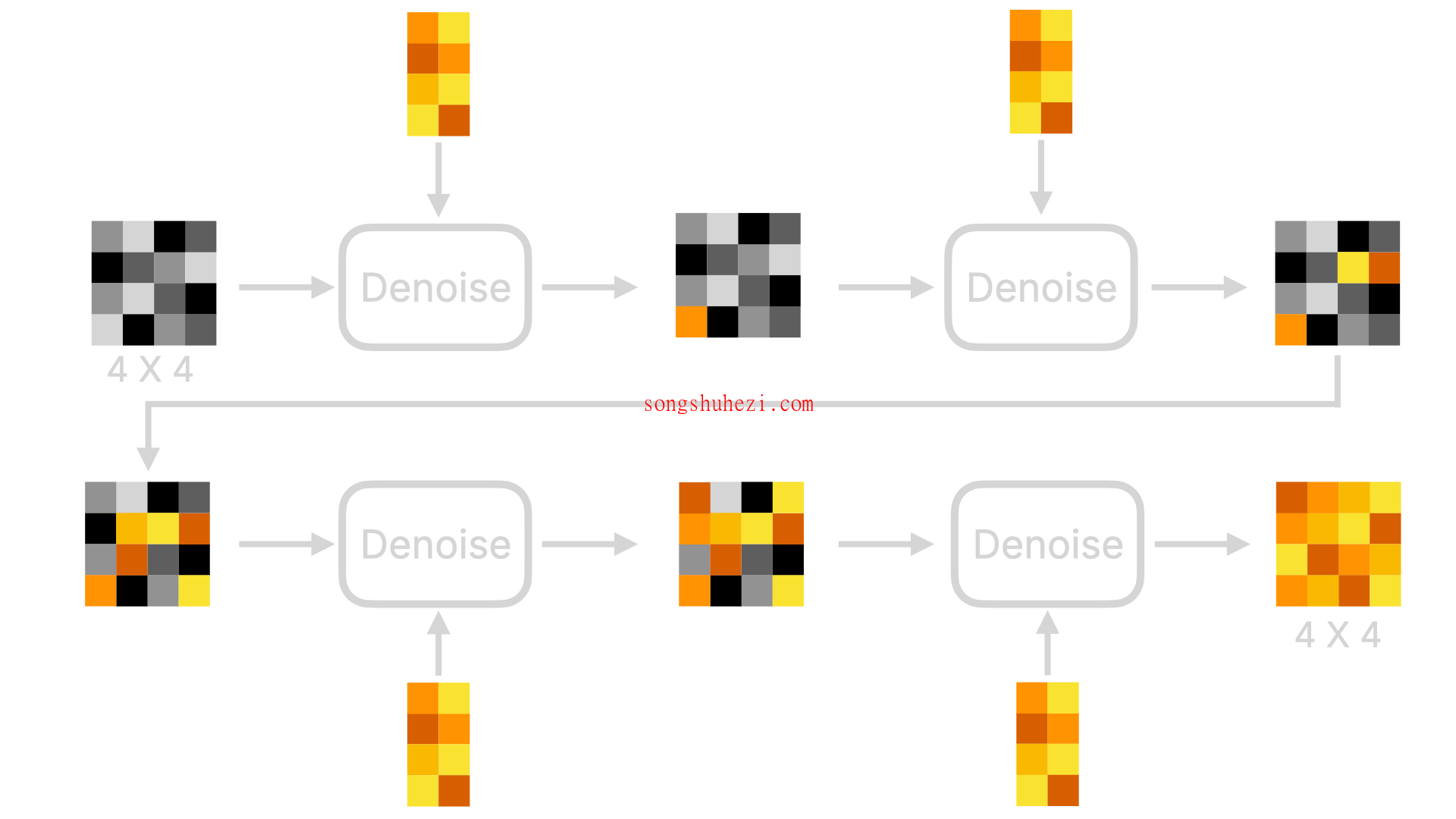
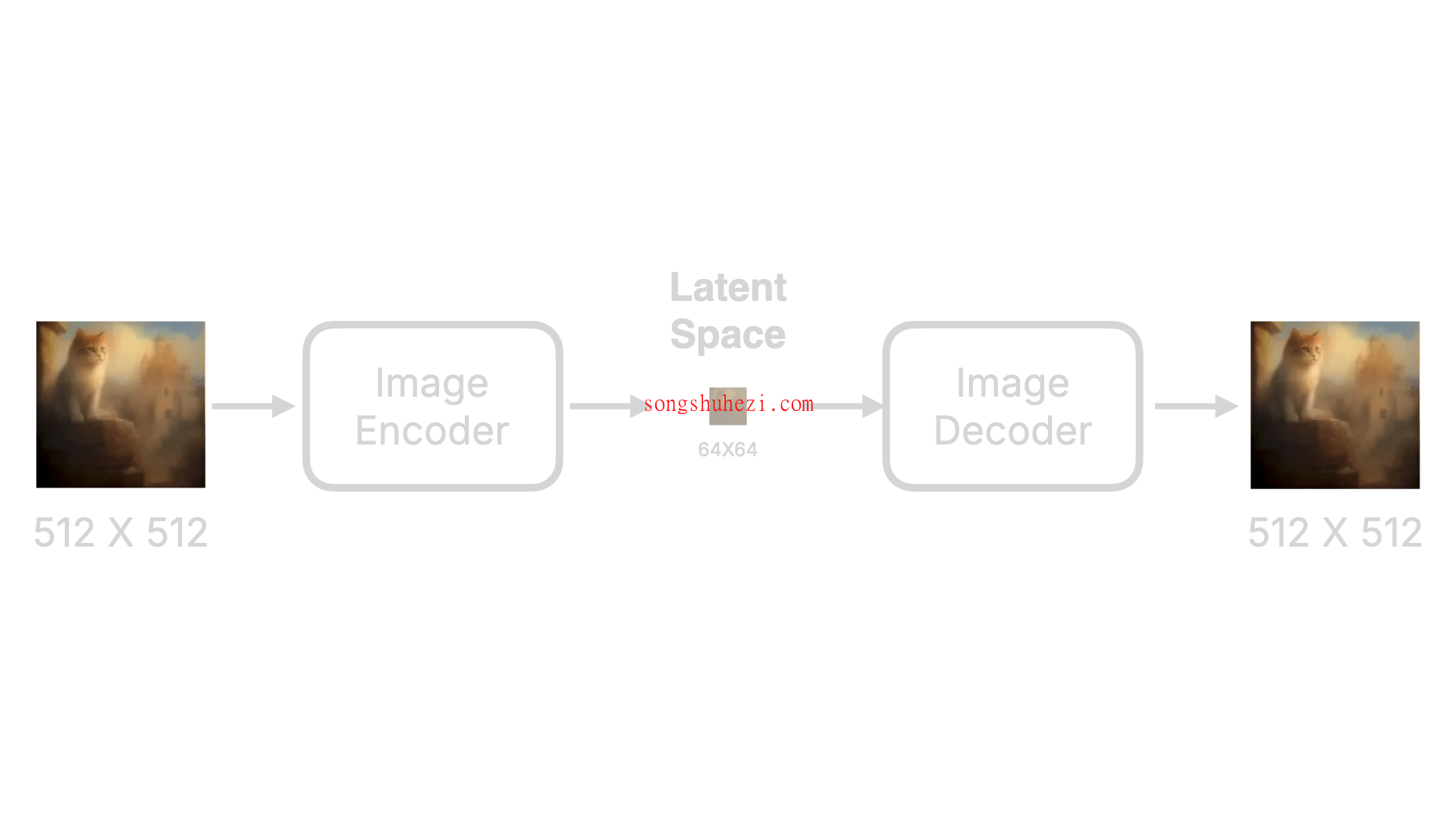
Image Decoder:最后,将经过多次降噪的中间数据转换为清晰的最终图像。这一步骤通常使用一个称为变分自编码器(VAE)的网络结构来完成,它能够保持图像的细节和质量。
ComfyUI 中的应用
在 ComfyUI 中,你将直接使用这些概念来实现具体的图像生成任务。例如,当你在 ComfyUI 中输入一个 Prompt 并启动图像生成时,实际上是在进行以下操作:
- 设置 Prompt:你输入的每一个词汇和描述都将通过 Text Encoder 转换成向量,这些向量会直接影响最终图像的生成。
- 调整参数:在 ComfyUI 中,你可以调整生成图像的相关参数,如迭代次数、噪音级别等,这些直接关联到 Image Information Creator 的工作过程。
- 结果预览:通过 Image Decoder 生成的最终图像将在界面上显示,让你直观地看到输入 Prompt 和参数设置的效果。
图像生成的实际操作
在 ComfyUI 中操作时,你会发现不同于传统图像编辑软件的直接和可视化操作,AI 绘图工具更多的是通过“指导”AI来实现创意的转换。例如,通过调整 Prompt 的细节描述,你可以影响 AI 如何理解和生成图像内容,这种方式虽然有随机性,但同时也充满无限可能。
希望通过这一系列的介绍,你能够对 Stable Diffusion 和 ComfyUI 有一个全面的理解,并能够在实际操作中更加得心应手。在接下来的教程中,我们将深入到 ComfyUI 的具体操作和高级功能,帮助你更好地掌握这一强大工具。

反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“AI绘画教程网”或者“aihuihua404” 或微信扫描上方二维码关注微信公众号



 RSS
RSS