




在Stable Diffusion上如何从图像中获取提示词?
你是否见过一张你非常喜欢的AI生成图像,并想知道是怎样的提示语生成的?本文将介绍几种从图像获取提示语的方法,并学习一些技巧来提高重现图像的可能性。
软件设置
我们将在本教程中使用AUTOMATIC1111稳定扩散WebUI。
这是一款流行且免费的软件,可以在Windows、Mac或Google Colab上使用。
方法1:通过读取PNG信息获取图像提示语
如果AI生成的图像是PNG格式,你可以尝试查看提示语和其他设置信息是否写在了PNG的元数据字段中。
首先,将图像保存到本地存储中。
打开AUTOMATIC1111 WebUI,导航至PNG信息页面。
将图像拖放到左侧的源画布上。
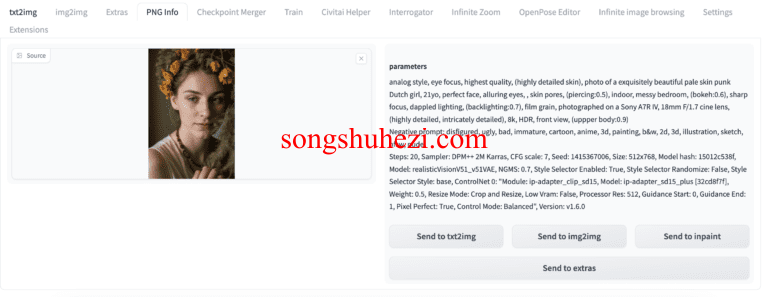
如果图像文件中包含提示语、反向提示语和其他生成参数,你将在右侧看到这些信息。你可以选择将提示语和设置发送至txt2img、img2img、修复或额外页面进行放大。
你也可以使用这个免费网站查看PNG元数据,而无需使用AUTOMATIC1111。
方法2:使用CLIP审问器猜测图像提示语
通常情况下,第一种方法不起作用。生成信息可能根本没有写入,或者在图像优化过程中被Web服务器去除,或者图像不是由稳定扩散生成的。
在这种情况下,你的下一个选项是使用CLIP审问器。它是一类AI模型,可以猜测图像的标题。它适用于任何图像,不仅仅是AI图像。
CLIP是什么
CLIP(Contrastive Language–Image Pre-training)是一种将视觉概念映射到自然语言的神经网络。CLIP模型通过大量的图像和标题对进行训练。
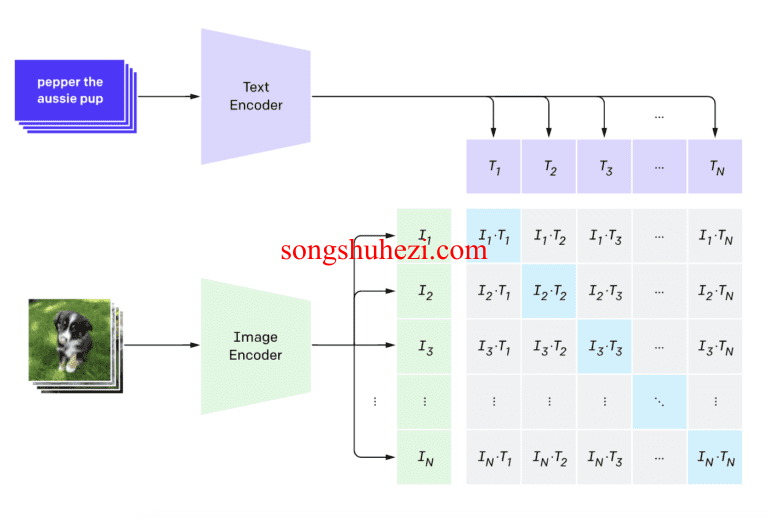
给定一张图像,CLIP模型可以推断描述图像的标题。在我们的案例中,你可以使用这个标题作为提示语。
如果你不想安装任何扩展,你可以使用AUTOMATIC1111的原生CLIP审问器,它位于img2img页面上。它使用的是BLIP
要使用原生CLIP审问器:
1.打开AUTOMATIC11111。 导航至img2img页面。
2.上传图像至img2img画布。
3.点击“审问CLIP”获取提示语。
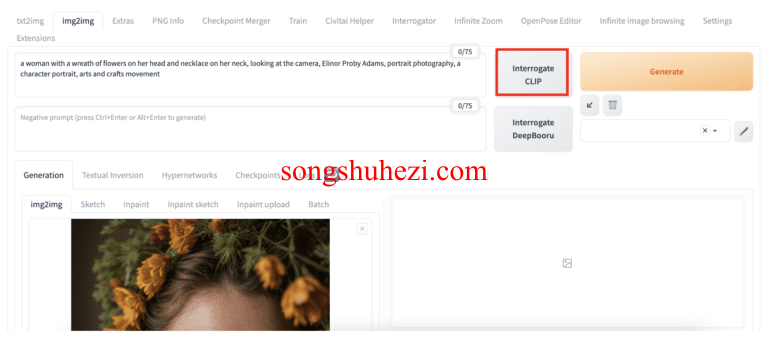
测试这个提示语与Realistic Vision模型和一个针对真实人物的负面提示语,我们得到了以下图像。
a woman with a wreath of flowers on her head and necklace on her neck, looking at the camera, Elinor Proby Adams, portrait photography, a character portrait, arts and crafts movement

CLIP审问器扩展
AUTOMATIC1111的原生CLIP审问器不允许你使用不同的CLIP模型。
如果你想要额外的功能,必须使用CLIP审问器扩展。
遵循推荐扩展页面上的说明进行安装。这是扩展的URL:
https://github.com/pharmapsychotic/clip-interrogator-ext
要使用CLIP审问器扩展:
1.打开AUTOMATIC1111 WebUI。 导航至审问器页面。
2.上传图像至图像画布。
3.在CLIP模型下拉菜单中选择ViT-L-14-336/openai。这是在稳定扩散v1.5中使用的语言嵌入模型。
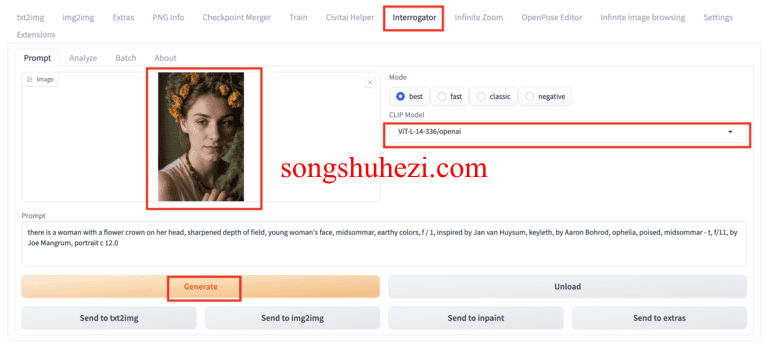
点击生成以产生提示语。
这是我们得到的提示语。
there is a woman with a flower crown on her head, with depth of field, earthy tones, marigold, portrait of a cute woman, dryad, subject centered in frame, of a young woman, midsommar, portrait face, 65mm 1.5x anamorphic lens, inspired by Elsa Beskow, art : : professional photograph, druid portrait

我们使用与上一节相同的图像设置得到了以下图像。
再次,它接近但并不完全相同。在提示语中缺少了她的项链,因此在图像中也没有。由于CLIP审问器的结果相当变化,我不会说ViT-L-14-336/openai模型比BLIP更差。
对于SDXL模型审问CLIP 如果提示语意图用于稳定扩散XL(SDXL)模型,你可以在审问页面的CLIP模型下拉菜单中选择ViT-g-14/laion2b_s34b_b88k。
这会给出以下提示语。
there is a woman with a flower crown on her head, medium portrait top light, f / 1, extra – details, 1 8 yo, national geographic photo shoot, movie scene portrait closeup, inspired by William Morris, center frame portrait, lut, warm glow, bio-inspired, at home, f / 2 0, by Jane Kelly
我们使用SDXL 1.0基础+精炼模型生成了图像。

提示语和模型确实产生了更接近原始构图的图像。
复制AI图像的技巧
你应该总是首先尝试PNG信息方法(方法1)从图像中获取提示语,因为如果幸运的话,它会给你完整的信息来重现图像。这包括提示语、模型、采样方法、采样步骤等。
你可以尝试使用BLIP和稳定扩散v1.5和XL模型的CLIP模型。ViT-g-14/laion2b_s34b_b88k与v1.5模型一起使用可能效果很好,不仅仅是SDXL。
不要犹豫修改提示语。如上例所示,提示语可能不正确或缺少一些对象。相应地编辑提示语以正确描述图像。
选择合适的检查点模型很重要。提示语不一定包含正确的风格。例如,如果你想生成逼真的人物,请选择一个逼真的模型。
最后,最终手段是使用图像提示语。SD v1.5 Plus模型可以在适当的提示语下忠实地复制一个图像。








 RSS
RSS