






WuDao-Model:多维度开源模型的突破与应用
多领域的开源模型,从图文交互到法律长文本
直达下载
返回上一页
描述
WuDao-Model通过多维度开源模型展现出在多领域的应用潜力,从图文生成到法律文本分析,体现了技术的广泛适用性和创新前景。
介绍
WuDao-Model汇集了多种领域的开源模型,旨在推动人工智能技术的广泛应用和发展。该项目包含了从图文生成到文本理解和生成、再到专业领域如法律和蛋白质研究的先进模型。
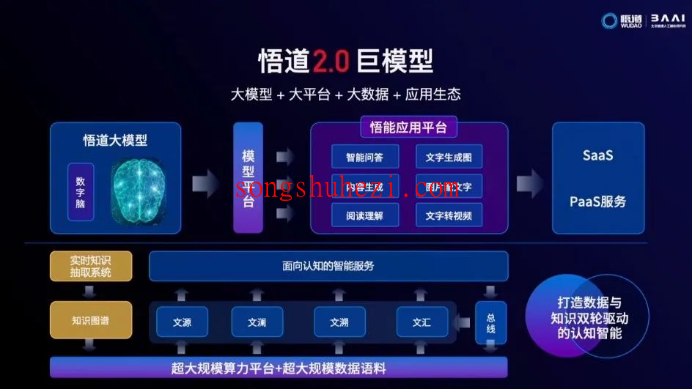
主要模型介绍
- 图文类模型
- CogView:拥有40亿参数的图文生成模型,能够基于文本内容生成各种风格的图像,如国画和油画等。在MS COCO的图文生成任务中,CogView的表现超过了OpenAI的DALL·E,达到了世界领先水平。
- BriVL:作为首个中文图文多模态大规模预训练模型,BriVL在图文检索任务上表现卓越,超越了同期的多模态预训练模型如UNITER和CLIP。
- 文本类模型
- GLM:以英语为核心,覆盖从1.1亿到1000亿参数的多规模预训练语言模型,其表现在语言理解和生成任务上均优于传统模型如BERT和T5。
- CPM:支持中文和中英双语的预训练语言模型,具备优秀的理解与生成能力,已公开多个规模版本,包括26亿和1980亿参数模型。
- Transformer-XL:专注于中文的预训练语言生成模型,参数规模为29亿,支持多种自然语言生成任务。
- EVA:作为目前最大的汉语对话模型,EVA在开放领域对话中表现出色,参数量达到28亿。
- Lawformer:世界首创的法律领域长文本中文预训练模型,拥有1亿参数,专门为法律文本设计。
- 蛋白质类模型
- ProtTrans:国内最大的蛋白质预训练模型,参数总量为30亿,推动生物医学研究的深入发展。
应用前景与技术优势
- 技术创新:这些模型的开发不仅推动了人工智能技术在特定领域的应用,也展示了大规模预训练模型在实际问题解决中的潜力。
- 多领域应用:从艺术创作到法律分析,悟道项目的模型能够广泛应用于各种专业领域,提供更精确、更高效的解决方案。
看到这些WuDao-Model的开源模型,真的让人感觉到技术的力量是如此的惊人。特别是像CogView这样能把文字变成画作的模型,每次看到都觉得像是魔法一样,非常酷!而那些专业领域的模型,比如Lawformer和ProtTrans,虽然听起来很专业,但知道它们可以帮助律师和科学家们解决实际问题,就感觉这技术真的很有用。
×
直达下载
反爬虫抓取,人机验证,请输入验证码查看内容
请扫描上方公众号二维码,发送关键字:2024,获取验证码。
微信搜索公众号:“程序员老鬼”或者“chatgpt1499” 或微信扫描右侧二维码关注微信公众号





类别
×
初次访问:反爬虫,人机识别
反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“程序员老鬼”或者“chatgpt1499” 或微信扫描右侧二维码关注微信公众号



 RSS
RSS