






PanGu-Alpha:在文本生成和处理领域展现出前所未有的能力
鹏城实验室创新的2000亿参数模型,开启智能语言处理的新篇章
直达下载
返回上一页
描述
PanGu-Alpha模型凭借其先进的技术和强大的参数规模,在文本生成和处理领域展现出前所未有的能力。
介绍
PanGu-Alpha是由鹏城实验室领导的技术团队开发的,是首个基于“鹏城云脑Ⅱ”和国产MindSpore框架开发的中文自回归语言模型,具有2000亿参数。此模型在2048卡的算力集群上进行了大规模分布式训练,标志着中文预训练语言模型的一个重要突破。
技术创新和应用领域
- 自回归语言模型:PanGu-Alpha采用自回归技术进行语言生成,使其在文本生成应用中,如知识问答、知识检索及阅读理解等,表现出色。
- MindSpore并行技术:利用MindSpore框架的自动并行计算功能,有效管理大规模参数,优化训练效率和模型性能。
- 广泛的应用场景:该模型不仅适用于普通的文本生成任务,还能进行小样本学习,展现了卓越的适应性和灵活性。
模型训练和数据集
- 海量语料训练:团队收集了近80TB的原始数据,经过精细的数据清洗和处理,构建了大约1.1TB的高质量中文语料库,确保了模型的训练质量和无偏性。
- 模型结构:PanGu-Alpha的核心是基于Transformer架构,增加了query层,优化了生成文本的连贯性和准确性。
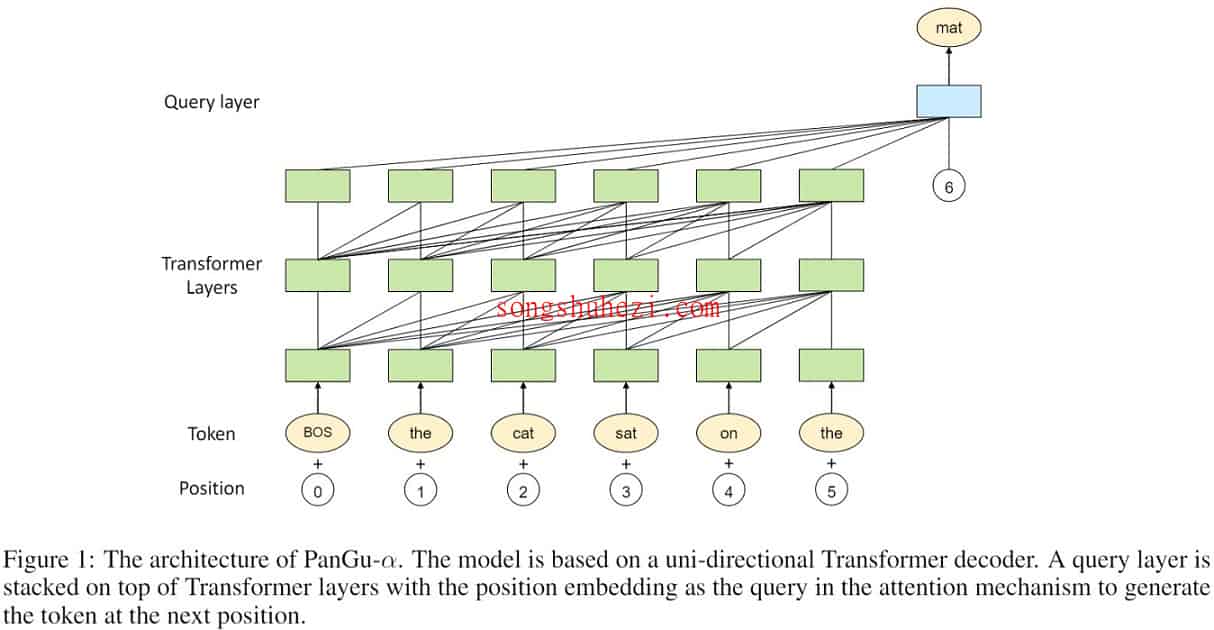
模型下载与部署
- 模型下载:用户可以通过链接下载不同配置的模型,如2.6B参数至200B参数模型,以满足不同的计算需求和应用场景。
- 环境配置:详细说明了在Ascend 910硬件上部署模型的环境要求,包括操作系统、框架及必要的软件包。
应用示例与评测
- 模型应用:提供了丰富的应用示例和指南,帮助用户快速将PanGu-Alpha部署于实际的业务场景中。
- 模型评测:通过多个下游任务展示了模型的性能,特别是在小样本学习能力上,与其他模型进行了对比,显示了其优越的语言理解和生成能力。
PanGu-Alpha在自动并行处理和大规模数据训练方面的创新,为未来的语言模型研究和应用提供了新的方法和思路。特别是其在小样本学习和复杂文本生成任务中表现出的卓越能力。
×
直达下载
反爬虫抓取,人机验证,请输入验证码查看内容
请扫描上方公众号二维码,发送关键字:2024,获取验证码。
微信搜索公众号:“程序员老鬼”或者“chatgpt1499” 或微信扫描右侧二维码关注微信公众号





类别
×
初次访问:反爬虫,人机识别
反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“程序员老鬼”或者“chatgpt1499” 或微信扫描右侧二维码关注微信公众号



 RSS
RSS