






Chinese-LLaMA-Alpaca-3:为中文自然语言处理领域带来了前所未有的开放性
LLaMA和Alpaca模型在中文环境中的应用与优化
直达下载
返回上一页
描述
Chinese-LLaMA-Alpaca-3项目为中文自然语言处理领域带来了前所未有的开放性和技术深度,通过开源模型和全面的技术文档,推动中文NLP技术向前发展。
介绍
Chinese-LLaMA-Alpaca-3项目现已全面启动,旨在进一步推动中文自然语言处理技术的发展与创新。此项目通过开源中文LLaMA模型和经过指令精调的Alpaca大模型,为中文NLP社区提供了一套完整的研究和应用框架。
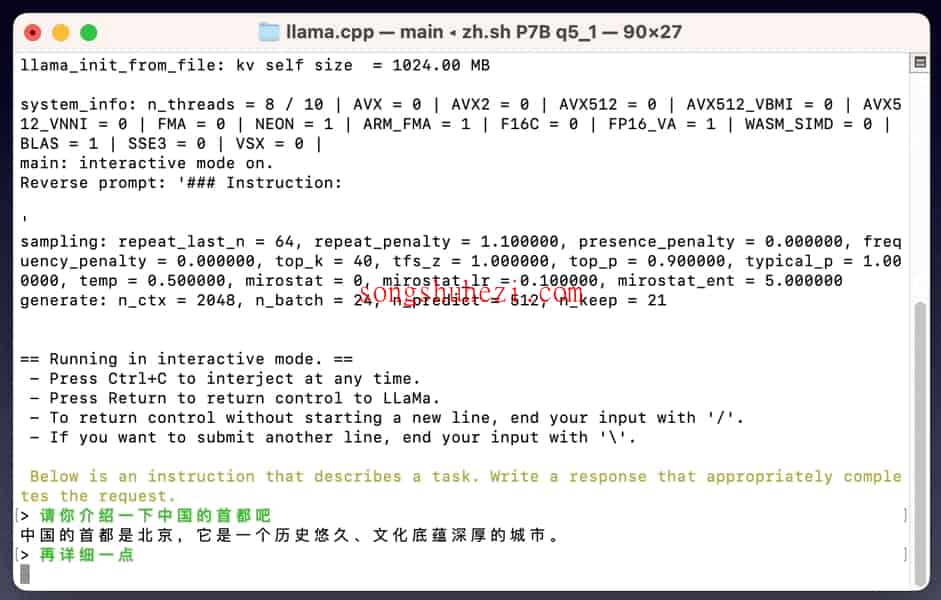
项目核心内容:
- 中文词表的扩展:在原版LLaMA模型的基础上,扩充了中文词表,有效提高了中文文本的编解码效率。
- 中文数据的二次预训练:利用丰富的中文文本数据对模型进行二次预训练,显著增强了模型的中文基础语义理解能力。
- 中文指令数据的精调:通过对中文Alpaca模型使用中文指令数据进行精调,大幅提升了模型对复杂指令的理解和执行能力。
- 开源预训练和指令精调脚本:项目不仅开放了模型,还提供了完整的预训练和指令精调脚本,使用户能够根据自己的需要进一步训练和优化模型。
- 多平台部署支持:支持在个人PC的CPU/GPU上快速部署和本地量化,使大模型的应用更加便捷和灵活。
项目亮点:
- 技术报告:详细的技术报告提供了模型训练和优化的全面细节,助力研究人员和开发者深入了解模型的内部机制和优化策略。
- 模型多样性:项目已开源多个版本的模型,包括7B、13B及33B,满足不同计算能力和应用需求。
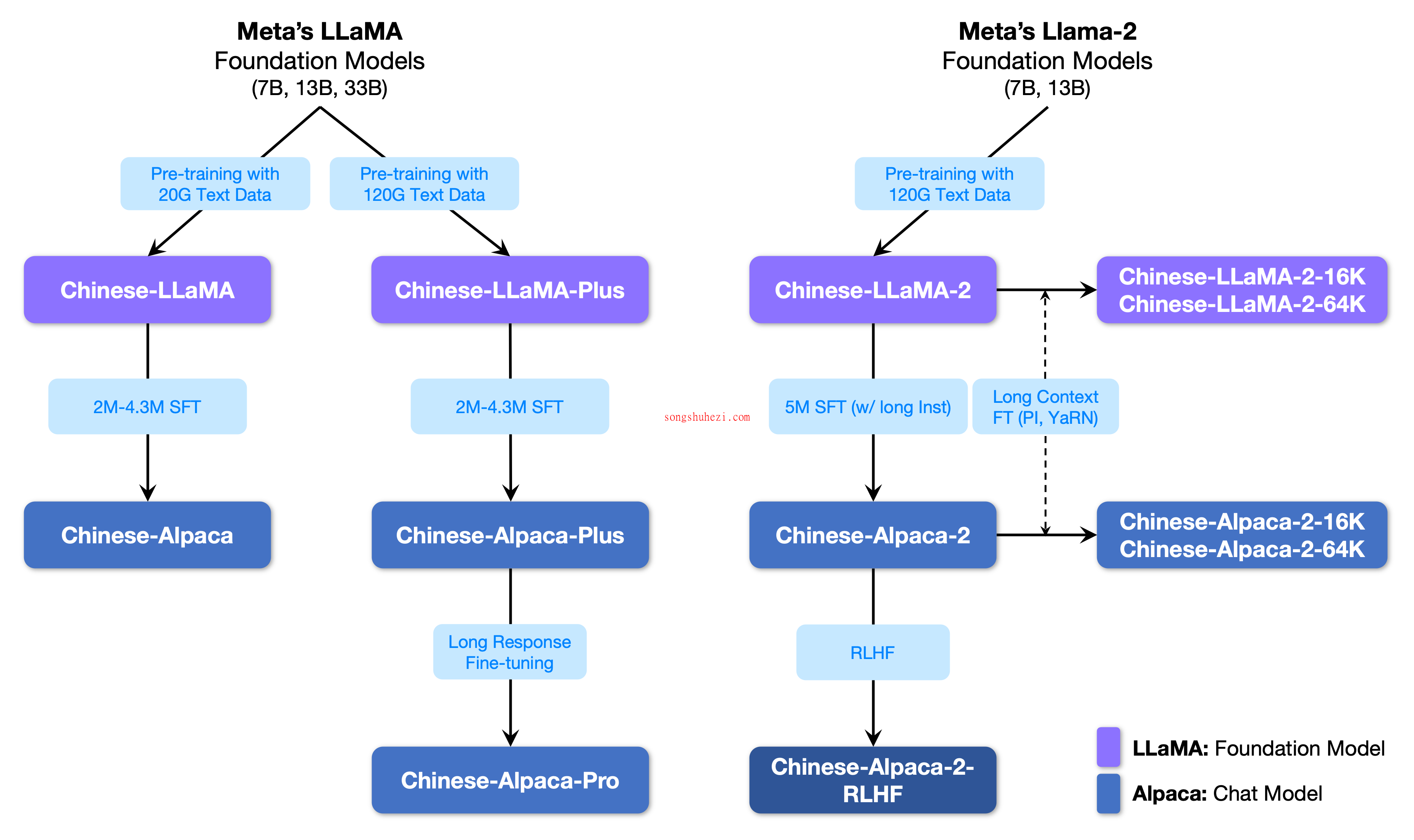
- 生态系统兼容性:完整支持🤗transformers, llama.cpp, text-generation-webui等多种工具和框架,提高了模型的适用范围和易用性。
Chinese-LLaMA-Alpaca-3不仅使中文语言处理技术更加开放和透明,还通过提供高效的训练和部署工具,极大地促进了中文自然语言处理技术的实际应用。
×
直达下载
反爬虫抓取,人机验证,请输入验证码查看内容
请扫描上方公众号二维码,发送关键字:2024,获取验证码。
微信搜索公众号:“程序员老鬼”或者“chatgpt1499” 或微信扫描右侧二维码关注微信公众号





类别
×
初次访问:反爬虫,人机识别
反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“程序员老鬼”或者“chatgpt1499” 或微信扫描右侧二维码关注微信公众号



 RSS
RSS