






Qwen-7B:超大规模语言模型
超大规模语言模型Qwen-7B的技术优势与应用
Qwen-7B,由阿里云研发的最新大规模语言模型,拥有高达70亿的参数量,是通义千问系列中的一员。这款基于Transformer架构的模型,在巨量的预训练数据集上完成训练,数据类型丰富,包含网络文本、专业书籍和代码等,确保了模型在多个领域的适应性和优秀的性能表现。
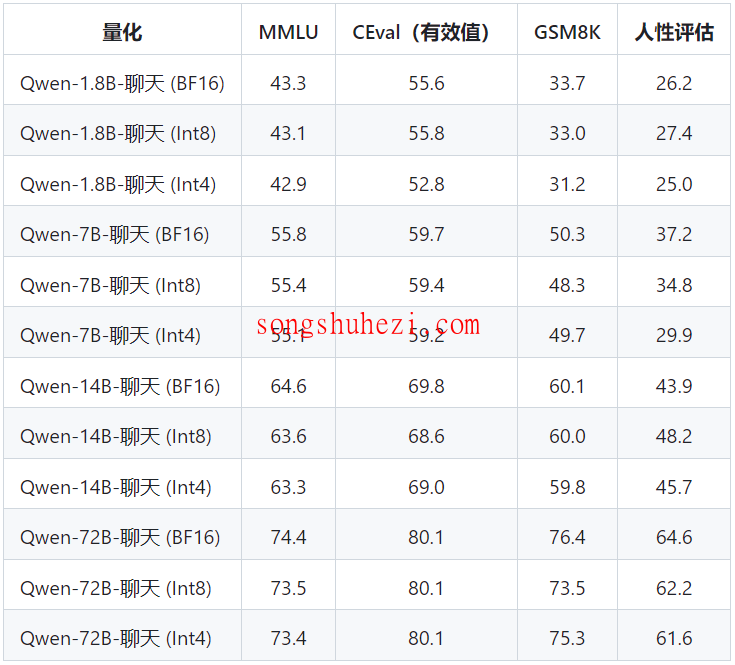
Qwen-7B不仅在自然语言理解与生成方面有着卓越的表现,其在数学问题解决、代码生成等多个复杂任务上也显示出了较同规模模型更优的性能。此外,模型支持多语言处理,使得用户在构建特定语言的模型时更为便捷。Qwen-7B的一个重要特点是其8K的超长上下文长度,这让模型能够处理更长的输入,提供更连贯的文本生成结果。
为了方便开发者使用,Qwen-7B支持通过 Transformers 库快速集成和使用。开发者只需要简单的安装和几行代码,就可以开始利用这一强大的模型进行各种自然语言处理任务。
pip install -r requirements.txt
特别是对于需要高显存效率的应用,开发者可以选择开启bf16或fp16精度,以优化性能并减少资源消耗。
git clone -b v1.0.8 https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .
pip install csrc/layer_norm
pip install csrc/rotary
在实际应用中,无论是通过简单的命令行交互,还是整合进复杂的业务流程中,Qwen-7B都能提供强大支持,帮助用户解决各种语言处理任务。例如,通过ModelScope平台,用户可以实现低成本、灵活的模型服务,这一平台特别适用于AI开发者。
import os
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
from modelscope import snapshot_download
model_id = 'QWen/qwen-7b-chat'
revision = 'v1.0.0'
model_dir = snapshot_download(model_id, revision)
pipe = pipeline(
task=Tasks.chat, model=model_dir, device_map='auto')
history = None
text = '浙江的省会在哪里?'
results = pipe(text, history=history)
response, history = results['response'], results['history']
print(f'Response: {response}')
text = '它有什么好玩的地方呢?'
results = pipe(text, history=history)
response, history = results['response'], results['history']
print(f'Response: {response}')
Qwen-7B在进行长文本分析时,它能够连贯地理解整体内容,输出连续且逻辑清晰的文本,这在以往的模型中很难见到。此外,其多语言支持也让我在处理非英语数据时倍感轻松。使用过程中,模型的响应速度和处理精度都达到了预期,这使得我的工作效率大大提升。

反爬虫抓取,人机验证,请输入验证码查看内容
请扫描上方公众号二维码,发送关键字:2024,获取验证码。
微信搜索公众号:“程序员老鬼”或者“chatgpt1499” 或微信扫描右侧二维码关注微信公众号






反爬虫抓取,人机验证,请输入验证码查看内容
请关注本站公众号回复关键字:“2024”,获取验证码。
微信搜索公众号:“程序员老鬼”或者“chatgpt1499” 或微信扫描右侧二维码关注微信公众号



 RSS
RSS